A proposal for a modern build-system

Hi. I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build. I have a solution for that. I am sending this paper (Making some final edits) https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... , which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed. My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it). HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence. The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get >3x faster compilation as well. Best, Hassan Sajjad
The interactions to reproduce the results. https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp On Wed, Apr 16, 2025, 16:34 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
I have a solution for that. I am sending this paper (Making some final edits) https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... , which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed.
My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it).
HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence.
The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get >3x faster compilation as well.
Best, Hassan Sajjad
Hi. I am seeking an endorsement of my software, HMake ( a library in a way (hconfigure) ), so that it can go through the review and possibly be included in Boost as a modern replacement for b2. Following is a comprehensive list of benefits that HMake provides compared to b2 or other build-systems. Some of this might not apply to one or the other. 1) Using C++ itself. You have to learn a library interface, but not a new programming language. 2) Single file for the whole build specification. 3) Needs very little maintenance or build-file modifications. You can use globbing patterns for specifying source and module files. Specifying tests can also be made simpler, e.g., with a convention to prepend a character in the file-name like (r, c), etc. (run, compile). And a JSON file if you expect any run to produce a particular output. So, you reconfigure when you add/delete a new test or modify the JSON file instead of first editing the build file. hmake.cpp file size is up to 10x smaller compared to CMakeLists due to C++ expressibility. 4) Very performant and efficient. On par with Ninja in both metrics, if not better. Some optimizations are still under development. 5) Multiconfig. You can build multiple configurations with one command. Has b2-inspired features/properties. 5) Fast configuration. Configuration will always be less than 5s ( even with up to 10 full Boost configurations on Windows ). 6) Very Extensible. Can be easily extended to support features like code generation, etc. The build algorithm allows for dynamic nodes and edges in the same process. No other does that. 7) Has header-units support, which, contrary to C++ modules, offers build-speed improvements without any source-code changes. The following are not yet implemented. But if you evaluate the above points, you can see that the following can be easily supported as well. 8) I wrote this paper https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper.... It is at most a 2-day work for a compile-dev to support this. This will allow 4x compilation speed improvement for Boost and even bigger gains for bigger projects. 9) HMake will support a feature called BigHu (described in previous email), which makes rebuilds incredibly fast as well. Also, I think header-units can be backported for older C++ versions as well, since they change semantics very little ( mostly around the preprocessor ). 10) HMake will also support https://lists.isocpp.org/sg15/2023/11/2146.php and https://lists.isocpp.org/sg15/2023/11/2106.php if these get implemented. 11) compile-commands.json support. HMake will generate these at configure time for the configurations being configured. 12) CMake integration support through CPS. Some features, like header-units might not work. 13) HMake will support multiple other programming languages, frameworks like iOS and Android app generation, different installers, etc. HMake is still a novel build-system that is under heavy development. A project of Boost size using this in production will provide highly valuable insights that will tremendously improve the HMake itself as well. HMake is written in C++20, follows best practices, is extensively tested, uses TDD, and the core library is around 15k C++ lines. I can also do a video call presentation of my software. This might be a quicker way to make yourself familiar with my software capabilities than reading documentation. Because I can do live examples and explain details accordingly. Best, Hassan Sajjad On Wed, Apr 16, 2025 at 5:21 PM Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
The interactions to reproduce the results. https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp
On Wed, Apr 16, 2025, 16:34 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
I have a solution for that. I am sending this paper (Making some final edits) https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... , which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed.
My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it).
HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence.
The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get >3x faster compilation as well.
Best, Hassan Sajjad
Hi. I would like to share a little more info. The speedup mentioned (1.44x) was achieved in Release config. I tested in Deubg config as well. Speed-up was 1.89x. So, the expected speed-up would be >3x in Release and >5x in Debug for the full Boost. Best, Hassan Sajjad On Sat, Apr 19, 2025, 22:19 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I am seeking an endorsement of my software, HMake ( a library in a way (hconfigure) ), so that it can go through the review and possibly be included in Boost as a modern replacement for b2.
Following is a comprehensive list of benefits that HMake provides compared to b2 or other build-systems. Some of this might not apply to one or the other.
1) Using C++ itself. You have to learn a library interface, but not a new programming language. 2) Single file for the whole build specification. 3) Needs very little maintenance or build-file modifications. You can use globbing patterns for specifying source and module files. Specifying tests can also be made simpler, e.g., with a convention to prepend a character in the file-name like (r, c), etc. (run, compile). And a JSON file if you expect any run to produce a particular output. So, you reconfigure when you add/delete a new test or modify the JSON file instead of first editing the build file. hmake.cpp file size is up to 10x smaller compared to CMakeLists due to C++ expressibility. 4) Very performant and efficient. On par with Ninja in both metrics, if not better. Some optimizations are still under development. 5) Multiconfig. You can build multiple configurations with one command. Has b2-inspired features/properties. 5) Fast configuration. Configuration will always be less than 5s ( even with up to 10 full Boost configurations on Windows ). 6) Very Extensible. Can be easily extended to support features like code generation, etc. The build algorithm allows for dynamic nodes and edges in the same process. No other does that. 7) Has header-units support, which, contrary to C++ modules, offers build-speed improvements without any source-code changes.
The following are not yet implemented. But if you evaluate the above points, you can see that the following can be easily supported as well.
8) I wrote this paper https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper.... It is at most a 2-day work for a compile-dev to support this. This will allow 4x compilation speed improvement for Boost and even bigger gains for bigger projects. 9) HMake will support a feature called BigHu (described in previous email), which makes rebuilds incredibly fast as well. Also, I think header-units can be backported for older C++ versions as well, since they change semantics very little ( mostly around the preprocessor ). 10) HMake will also support https://lists.isocpp.org/sg15/2023/11/2146.php and https://lists.isocpp.org/sg15/2023/11/2106.php if these get implemented. 11) compile-commands.json support. HMake will generate these at configure time for the configurations being configured. 12) CMake integration support through CPS. Some features, like header-units might not work. 13) HMake will support multiple other programming languages, frameworks like iOS and Android app generation, different installers, etc.
HMake is still a novel build-system that is under heavy development. A project of Boost size using this in production will provide highly valuable insights that will tremendously improve the HMake itself as well. HMake is written in C++20, follows best practices, is extensively tested, uses TDD, and the core library is around 15k C++ lines.
I can also do a video call presentation of my software. This might be a quicker way to make yourself familiar with my software capabilities than reading documentation. Because I can do live examples and explain details accordingly.
Best, Hassan Sajjad
On Wed, Apr 16, 2025 at 5:21 PM Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
The interactions to reproduce the results. https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp
On Wed, Apr 16, 2025, 16:34 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
I have a solution for that. I am sending this paper (Making some final edits) https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... , which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed.
My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it).
HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence.
The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get >3x faster compilation as well.
Best, Hassan Sajjad

Hi,
Following is a comprehensive list of benefits that HMake provides compared to b2 or other build-systems.
Generally speaking your "benefits list" has quite bold statements Are you proposing replacement of b2 for Boost or just yet another build system to the club?
1) Using C++ itself. You have to learn a library interface, but not a new programming language.
And why is it good? I mean you need to have a really good point to make build system that uses C++ files to define a build...
4) Very performant and efficient. On par with Ninja in both metrics, if not better. Some optimizations are still under development.
So how would it be better than just old good cmake + ninja? I mean today CMake is the most common industry standard build system that works really well. Why would you want to use it over something like this? Serious question that needs a deep answer.
5) Fast configuration. Configuration will always be less than 5s ( even with up to 10 full Boost configurations on Windows ).
See build systems run multiple tests (cmake, autotools and others) to make sure that everything is as expected. How exactly do you think you'll be able to speed it up? Because most of the configuration time is actually performing checks like potential dependencies, test builds, etc. Now I don't want to discourage you but it is a really non-standard approach to build. And on more technical details: while it is more than ok to share ideas, generally speaking seeking of an endorsement is something done to get ready for a review... Not sure it is even close to it. Regards, Artyom
Generally speaking your "benefits list" has quite bold statements
Are you proposing replacement of b2 for Boost or just yet another build system to the club?
These statements are based on concrete evidence. I am proposing to replace b2. And why is it good? I mean you need to have a really good point to make
build system that uses C++ files to define a build...
3x faster compilation in Release and >5x faster in Debug mode for Boost and better for bigger projects. No other build-system can do that. HMake will have a few other game-changing features in the future as well. It is not possible to evolve a DSL based build-system like that.
I mean today CMake is the most common industry standard build system
that works really well. Why would you want to use it over something like this?
CMake can not support C++20 header-units. One benefit that I forgot is that once you have compiled your project with header-units in HMake and you want to move to C++20 modules, you do not need to make a single edit in your configuration file (Not true for projects like Boost which want to support both header-files and modules. In this case some macro definitions will be needed). With this, #10 and #8, C++20 modules and header-units become an absolute bliss to use with HMake. See build systems run multiple tests (cmake, autotools and others) to make
sure that everything is as expected. How exactly do you think you'll be able to speed it up? Because most of the configuration time is actually performing checks like potential dependencies, test builds, etc.
By caching the results and not running tests every time. Also, configure.exe uses the same code that is used by build.exe. It is fully parallel as well. Now I don't want to discourage you but it is a really non-standard
approach to build.
Isn't it superior, though? And on more technical details: while it is more than ok to share ideas,
generally speaking seeking of an endorsement is something done to get ready for a review... Not sure it is even close to it.
How so? Best, Hassan Sajjad On Mon, May 5, 2025 at 5:49 PM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
Hi,
Following is a comprehensive list of benefits that HMake provides
compared
to b2 or other build-systems.
Generally speaking your "benefits list" has quite bold statements
Are you proposing replacement of b2 for Boost or just yet another build system to the club?
1) Using C++ itself. You have to learn a library interface, but not a new programming language.
And why is it good? I mean you need to have a really good point to make build system that uses C++ files to define a build...
4) Very performant and efficient. On par with Ninja in both metrics, if not better. Some optimizations are still under development.
So how would it be better than just old good cmake + ninja?
I mean today CMake is the most common industry standard build system that works really well. Why would you want to use it over something like this?
Serious question that needs a deep answer.
5) Fast configuration. Configuration will always be less than 5s ( even with up to 10 full Boost configurations on Windows ).
See build systems run multiple tests (cmake, autotools and others) to make sure that everything is as expected. How exactly do you think you'll be able to speed it up? Because most of the configuration time is actually performing checks like potential dependencies, test builds, etc.
Now I don't want to discourage you but it is a really non-standard approach to build.
And on more technical details: while it is more than ok to share ideas, generally speaking seeking of an endorsement is something done to get ready for a review... Not sure it is even close to it.
Regards, Artyom
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost

06.05.2025 00:59:04 Hassan Sajjad via Boost <boost@lists.boost.org>:
I am proposing to replace b2.
I have reservations about this. I am not in favor of rewriting the configuration selection for the various combinations of architecture, binary format, address model, and ABI. This would require significant effort and could introduce unnecessary complexity, given the work already invested in the current implementation.
I have reservations about this. I am not in favor of rewriting the configuration selection for the various combinations of architecture, binary format, address model, and ABI. This would require significant effort and could introduce unnecessary complexity, given the work already invested in the current implementation.
HMake API has features / properties inspired by / mapped on b2 features. On Tue, May 6, 2025 at 12:18 PM oliver.kowalke--- via Boost < boost@lists.boost.org> wrote:
06.05.2025 00:59:04 Hassan Sajjad via Boost <boost@lists.boost.org>:
I am proposing to replace b2.
I have reservations about this. I am not in favor of rewriting the configuration selection for the various combinations of architecture, binary format, address model, and ABI. This would require significant effort and could introduce unnecessary complexity, given the work already invested in the current implementation.
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
06.05.2025 20:37:08 Hassan Sajjad <hassan.sajjad069@gmail.com>:
I have reservations about this. I am not in favor of rewriting the configuration selection for the various combinations of architecture, binary format, address model, and ABI. This would require significant effort and could introduce unnecessary complexity, given the work already invested in the current implementation.
HMake API has features / properties inspired by / mapped on b2 features.
please provide an example for boost.context's
. I am proposing to replace b2.
While I can agree that b2 isn't particularly good build system by any stretch of imagination There was a long and yet incomplete effort of moving to CMake that most around there are familiar with. CMake works very well and is very well supported all around. Replacing one not-so-good homebrew system that was at least polished with yet another homebrew system is a horrible idea. Boost needs _less_ of "non-invented-here-syndrome": not _more_ of it Refrasing Stroustrup there are two types of build systems - everybody complains about and nobody uses, and cmake is one everybody is complaining about ;-)
I mean today CMake is the most common industry standard build system
that works really well. Why would you want to use it over something like this?
CMake can not support C++20 header-units. One benefit that I forgot is that once you have compiled your project with header-units in HMake and you want to move to C++20 modules,
It seems like a feature gap that can be fixed at CMake level - either by cmake developers or by external patch. Have you considered talking with CMake developers about it and/or submitting a patch? What do they think about this? I'm sure they are aware of the problem :-)
By caching the results and not running tests every time. Also, configure.exe uses the same code that is used by build.exe. It is fully parallel as well.
You don't reconfigure each and every build... cmake caches _a lot_ sorry but it seems to be a false statement. Best Artyom

On Tue, May 6, 2025 at 2:52 AM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
. I am proposing to replace b2.
While I can agree that b2 isn't particularly good build system by any stretch of imagination
Specific build systems, and all software, has advantages and disadvantages. We would benefit from feedback as to improvements we can make to our tools. -- -- René Ferdinand Rivera Morell -- Don't Assume Anything -- No Supongas Nada -- Robot Dreams - http://robot-dreams.net
On Tue, May 6, 2025 at 5:05 PM René Ferdinand Rivera Morell <grafikrobot@gmail.com> wrote:
On Tue, May 6, 2025 at 2:52 AM Artyom Beilis via Boost <boost@lists.boost.org> wrote:
. I am proposing to replace b2.
While I can agree that b2 isn't particularly good build system by any stretch of imagination
Specific build systems, and all software, has advantages and disadvantages. We would benefit from feedback as to improvements we can make to our tools.
See, I discussed it a lot back in 2011 on this list. As bottom line when I worked on Boost.Locale having large experience with both, autotools cmake and even basic makefiles I totally failed to perform all tasks I needed I don't recall exactly but basic stuff like finding 3rd party libraries or conditional builds was total nightmare and very hard to maintain. Compare for example cmake: https://github.com/boostorg/locale/blob/develop/CMakeLists.txt and jamfile https://github.com/boostorg/locale/blob/develop/build/Jamfile.v2 that is twice as large and some tests that are built in in cmake (like test header/library) are generated in separate build The concept of "conditional flags" per build makes anything beyond simple tasks very challenging I couldn't complete the build system on my own and Vladimir Prus had come to my rescue... Even after that I failed to create conditional tests (so I just put ifdef to make them do nothing) but I think Alexander Grund that took the maintenance from me and does absolutely amazing job had fixed it, Bottom line, in my opinion bjam is a very limited build system. Maybe it servers Boost ok, but I would never choose one outside the scope mostly due its design of doing everything in the same flow under all conditions rather than the much simpler and easy to use CMake approach. I don't tell cmake is perfect - ohhh boy it isn't but I find it much more manageable, easy to use and well documented. Maybe stuff had changed since 2011 but for me it was very unpleasant experience, and I worked with autotools that were surprisingly simpler to use (at least for me) So take my words with a grain of salt :-) Artyom

вт, 6 мая 2025 г. в 17:55, Artyom Beilis via Boost <boost@lists.boost.org>:
See, I discussed it a lot back in 2011 on this list.
As bottom line when I worked on Boost.Locale having large experience with both, autotools cmake and even basic makefiles I totally failed to perform all tasks I needed I don't recall exactly but basic stuff like finding 3rd party libraries or conditional builds was total nightmare and very hard to maintain.
Compare for example cmake: https://github.com/boostorg/locale/blob/develop/CMakeLists.txt and jamfile https://github.com/boostorg/locale/blob/develop/build/Jamfile.v2 that is twice as large and some tests that are built in in cmake (like test header/library) are generated in separate build
I looked at those two files. As far as I can see, the vast majority of that jamfile is configuring dependencies, particularly Iconv and ICU. The only reason there's nothing similar in the CMakeLists.txt is because there are Find modules for those libraries provided with CMake. Ironically enough, they were not provided with CMake in 2011 (FindICU is provided since version 3.7 which was released in 2016, FindIconv since version 3.11 released in 2018). Moreover, things like private/public properties were only added to CMake in 2013. Again, ironically as an effort to copy b2 usage requirements.
Bottom line, in my opinion bjam is a very limited build system. Maybe it servers Boost ok, but I would never choose one outside the scope mostly due its design of doing everything in the same flow under all conditions rather than the much simpler and easy to use CMake approach.
I can agree that it could be more easy to think in exactly one configuration. Which makes writing b2 build scripts properly more challenging than CMake build scripts. But ironically again, this part of b2 complexity also gradually enters CMake due to multiconfig generators (just look at generator expressions). Nevertheless, I find it strange that you call b2 very limited compared to CMake, when it's actually more powerful, and it's exactly that power that incurs complexity.
On Tue, May 6, 2025 at 10:39 PM Дмитрий Архипов via Boost <boost@lists.boost.org> wrote:
вт, 6 мая 2025 г. в 17:55, Artyom Beilis via Boost <boost@lists.boost.org>:
See, I discussed it a lot back in 2011 on this list.
As bottom line when I worked on Boost.Locale having large experience with both, autotools cmake and even basic makefiles I totally failed to perform all tasks I needed I don't recall exactly but basic stuff like finding 3rd party libraries or conditional builds was total nightmare and very hard to maintain.
Compare for example cmake: https://github.com/boostorg/locale/blob/develop/CMakeLists.txt and jamfile https://github.com/boostorg/locale/blob/develop/build/Jamfile.v2 that is twice as large and some tests that are built in in cmake (like test header/library) are generated in separate build
I looked at those two files. As far as I can see, the vast majority of that jamfile is configuring dependencies, particularly Iconv and ICU. The only reason there's nothing similar in the CMakeLists.txt is because there are Find modules for those libraries provided with CMake. Ironically enough, they were not provided with CMake in 2011 (FindICU is provided since version 3.7 which was released in 2016, FindIconv since version 3.11 released in 2018). Moreover, things like private/public properties were only added to CMake in 2013. Again, ironically as an effort to copy b2 usage requirements.
Actually in cppcms/booster.locale original cmake (where boost.locale came from) I used one liners to find headers and libraries only difference was for debug build to find iculibrary with "d" suffix, I didn't use predefined FindICU Now finding 3rd part library is the central part of the configuration/build system for real world projects. Looking as an example at my big FOSS C++ project dependencies CppCMS: icu, zlib, openssl/gnu-tls, iconv, pcre, python CppDB: mysql, odbc, postgresql, sqlite Dlprimitives: python, sqlite, OpenCL, protobuf, openblas/cblas, hdf5, boost-python, boost-numpy OpenLiveStacker: libtiff, cppcms, libcurl, indilib, indigo, libraw, libgphoto, opencv, cfitsio, libusb, asisdk, touptek sdk, zlib, android camera2 And finding each of them in CMake is virtually two lines (header, library) and I rarely use FindXXX with exception of some complex stuff (ironically boost python) So Boost is quite a unicorn when the vast majority of the libraries are header only or come with 0 dependencies and using icu in Regex in Locale was a major event. So from the point of view of somebody who comes from outside it is bare practicality and simplicity of using/configuring the dependencies.
Bottom line, in my opinion bjam is a very limited build system. Maybe it servers Boost ok, but I would never choose one outside the scope mostly due its design of doing everything in the same flow under all conditions rather than the much simpler and easy to use CMake approach.
I can agree that it could be more easy to think in exactly one configuration. Which makes writing b2 build scripts properly more challenging than CMake build scripts. But ironically again, this part of b2 complexity also gradually enters CMake due to multiconfig generators (just look at generator expressions). Nevertheless, I find it strange that you call b2 very limited compared to CMake, when it's actually more powerful, and it's exactly that power that incurs complexity.
I understand what you are talking about because for windows build there is a huge matrix of Under Windows {Release,Debug}x{DynamicLink,StaticLink}x{DynamicRuntime,StaticRuntime} And under Linux it is typically shared object and static object - BTW something that autotools did very well and drive me crazy at the beginning with CMake - autotools buid automatically shared object and static while in cmake it is more verbose Now typically under windows you have two Debug and Release runtimes because they are ABI incompatible (not going to why they did such a dreadful decision - but it is another topic) So there is a mode in cmake that tries to build them both - and it does not work well that is why I never support VS projects with dual builds in my cmakes and tell windows users grab ninja and do a separate build for each of the debub or release configurations. So yes for building crazy matrices bjam helps a lot I totally agree - but all this till you need to find appropriate dependency for each and every case and turn on/off a feature if you found it or not - and not it becomes a nightmare since you may found ICU for dynamic linking in release but not for static linking or not for debug. So I do understand practicality of Boost Build bjam for Boost itself (as long as you don't need any 3rd party) but I find it rather unpractical for outside of the Boost crib Artyom
On Tue, May 6, 2025 at 4:04 PM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
And finding each of them in CMake is virtually two lines (header, library) and I rarely use FindXXX with exception of some complex stuff (ironically boost python)
CMake does indeed have a really good support for finding & using external dependencies. But it has it at a rather large cost. My approach over the years has been to solve that problem for all build systems and package managers through interop standards. And since I have limited time means that other solutions for B2 specifically have not been followed on. But also recently I've implemented support in B2 that is a step towards easier use of external libs. Now typically under windows you have two Debug and Release runtimes
There's also RelWithDebInfo and MinSizeRel.
because they are ABI incompatible (not going to why they did such a dreadful decision - but it is another topic)
You might as well start assuming that everything is ABI incompatible if you want to prepare yourself for hardened std's. So I do understand practicality of Boost Build bjam for Boost itself
(as long as you don't need any 3rd party) but I find it rather unpractical for outside of the Boost crib
Understand. -- -- René Ferdinand Rivera Morell -- Don't Assume Anything -- No Supongas Nada -- Robot Dreams - http://robot-dreams.net

On Tue, May 6, 2025 at 12:52 AM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
. I am proposing to replace b2.
While I can agree that b2 isn't particularly good build system by any stretch of imagination
There was a long and yet incomplete effort of moving to CMake that most around there are familiar with. CMake works very well and is very well supported all around.
Replacing one not-so-good homebrew system that was at least polished with yet another homebrew system is a horrible idea.
Boost needs _less_ of "non-invented-here-syndrome": not _more_ of it
This actually seems like a fantastic time to shill this Python script I've been working on. It lives here: https://github.com/cmazakas/boost/blob/c2py/c2.py This is intended to be a full drop-in replacement for b2. Right now, it only works on Linux but that's because I want a quality implementation before I work on a cross-platform solution. I'm actually chatting with one of the CMake devs on slack about how to alter the generation of the Ninja files. I might just manually patch them myself in the interim though. You can invoke it similarly to b2 today: ./c2.py \ hash2 test \ --cxxstd 11,20 \ --variant debug,release \ --address-model 64 \ --toolset clang-19,gcc-14 \ --asan --ubsan \ --ctestflags="--output-on-failure -R 'xxh3'" \ --no-cmake \ -j20 What this tool does is, it generates a series of CMake build directories under `build_c2py`, configuring each project in parallel and then builds the tests in parallel using recursive Make invocations. It's not as fast as b2 is but because it uses CMake, it really, really opens up the door for us. I've been thinking about looking for beta testers. I use this script daily to drive my work with the Alliance. The script is woefully incomplete but I think it's a good first step. - Christian

Christian Mazakas wrote:
You can invoke it similarly to b2 today:
./c2.py \ hash2 test \ --cxxstd 11,20 \ --variant debug,release \ --address-model 64 \ --toolset clang-19,gcc-14 \ --asan --ubsan \ --ctestflags="--output-on-failure -R 'xxh3'" \
--output-on-failure (and --no_tests=error) should be the default, really.
--no-cmake \
What does --no-cmake do?
-j20
On Tue, May 6, 2025 at 7:46 AM Peter Dimov via Boost <boost@lists.boost.org> wrote:
Christian Mazakas wrote:
You can invoke it similarly to b2 today:
./c2.py \ hash2 test \ --cxxstd 11,20 \ --variant debug,release \ --address-model 64 \ --toolset clang-19,gcc-14 \ --asan --ubsan \ --ctestflags="--output-on-failure -R 'xxh3'" \
--output-on-failure (and --no_tests=error) should be the default, really.
Great call! I can update the script to do that trivially.
--no-cmake \
What does --no-cmake do?
I should update the name but it makes the script skip the CMake configuration phase. Right now, the script uses a very simple and naive mangling scheme for creating the names of build directories. A goal of mine was to have them be quasi-human readable so that way a frustrated user could intuitively inspect a specific build configuration so like b2, I don't include any passed cxxflags in the mangled name. To make sure that an accurate configuration is always used, I delete the existing CMakeCache.txt if it was there, which means a full re-configuration by CMake. `--no-cmake` is a flag used to skip this part and instead `make -C build_c2py` is invoked directly.
-j20
Ha, in the ideal world I suppose we'd check for the available number of CPUs and default to the max available. This is the value passed down to the Make invocation. - Christian
Christian Mazakas wrote:
-j20
Ha, in the ideal world I suppose we'd check for the available number of CPUs and default to the max available. This is the value passed down to the Make invocation.
And to CTest, I suppose? One annoying feature of CMake is that it's not possible to pass the -j option passed to CMake down to CTest (if you have a custom target running the tests.)
It seems like a feature gap that can be fixed at CMake level - either by cmake developers or by external patch.
Have you considered talking with CMake developers about it and/or submitting a patch? What do they think about this?
This is a little funny. If CMake developers can not, how can I? I can only talk about how my build-system supports header-units. Also, I should not have said, "CMake can not support C++20 header-units". Anything is possible. Header-Units support is built on the following four features in HMake. 1) Next-Gen build-algorithm HMake build-algorithm support both dynamic nodes and dynamic edges. CMake supports modules through Ninja, which only supports dynamic edges. Example6 and Example7 in HMake Architecture section demonstrate this capability. 2) Vertical Integration HMake is both a build-system generator and a build-system itself. Ninja supports dynamic edges through a separate process. While building modules, it launches a new process that consumes all of the scanning output and outputs a file in Ninja consumable format. Ninja then consumes this file to learn about the dynamic edges. While HMake does all of this itself. Suppose Ninja supports dynamic nodes, and even then, to ensure a header unit is built before the consumer, it will need to launch a new process to establish the dependency. It will have to do this every time it discovers a new header-unit. And even then, it will have to determine what compile-command to use with that header-unit. Suppose the user wants to build ASIO with ASIO_STANDALONE. Only the ASIO header-units should be built with this macro. ASIO header-units can potentially be discovered in any of its dependent targets. HMake goes over the list of header-unit-includes to determine the directory from which this header-unit is coming. And then the mapping of the directory to target to determine the cpptarget to attach this header-unit to. i.e the target whose compile-command will be used to compile this header-unit. Ninja lacks the context to do all this. CMake will have to turn to a build-system itself to support header-units. 3) Game-Changing Feature, Node HMake has another feature called Node (explained in documentation). For a module file, to support incremental build, HMake caches its header-includes, module-deps, header-unit-deps, compile-command, scanning-command. Without the Node feature, this cache will explode. Node feature results in little build residue. I estimate that for full Boost, for full Configuration, it will be 1MB. This ensures ultra-fast loading, ultra-fast performance. 4) C++ While this is often contended, I think this is extremely important. E.g., now I plan to remove the scanning support and add scanning-less support. C++ allows for quick iteration. It allows one to focus on the problem instead of the DSL. All in all, as it stands, this is a fundamental change. Best, Hassan Sajjad On Tue, May 6, 2025 at 12:52 PM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
. I am proposing to replace b2.
While I can agree that b2 isn't particularly good build system by any stretch of imagination
There was a long and yet incomplete effort of moving to CMake that most around there are familiar with. CMake works very well and is very well supported all around.
Replacing one not-so-good homebrew system that was at least polished with yet another homebrew system is a horrible idea.
Boost needs _less_ of "non-invented-here-syndrome": not _more_ of it
Refrasing Stroustrup there are two types of build systems - everybody complains about and nobody uses, and cmake is one everybody is complaining about ;-)
I mean today CMake is the most common industry standard build system
that works really well. Why would you want to use it over something like this?
CMake can not support C++20 header-units. One benefit that I forgot is that once you have compiled your project with header-units in HMake and you want to move to C++20 modules,
It seems like a feature gap that can be fixed at CMake level - either by cmake developers or by external patch.
Have you considered talking with CMake developers about it and/or submitting a patch? What do they think about this?
I'm sure they are aware of the problem :-)
By caching the results and not running tests every time. Also, configure.exe uses the same code that is used by build.exe. It is fully parallel as well.
You don't reconfigure each and every build... cmake caches _a lot_ sorry but it seems to be a false statement.
Best Artyom
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost

On 05/05/2025 23:45, Hassan Sajjad via Boost wrote:
Generally speaking your "benefits list" has quite bold statements
Are you proposing replacement of b2 for Boost or just yet another build system to the club?
These statements are based on concrete evidence. I am proposing to replace b2.
If I remember well, this is not the first time that you want to propose it, and I was against it for different reasons: - We are already trying to replace the build system with cmake. - CMake can have pros and cons, but actually it's one of biggest standard in C++ development. Changing a "boost only" build system for another system that will used only for boost (I don't see hmake widely used) it's pretty useless. - Che build speed-up can be good, but build boost it's not something that a normal user does every day, so in my personal opinion it's not a good reason to change the build system. - And I say "change" and not "add" because using three different build systems, b2, cmake and boost.build, it's a mess. The build system should be only one, apart the periods of time where we need to migrate from one system to another one. - Many people install and use boost with package managers like vcpkg and conan. HMake is not integrating well with those systems. The alternatives is that we need to do a lot of work in order to make it work with at least those package manager, or use other build systems for those and HMake for building boost without them. It's the previous point, we need to maintain a lot of different systems. All of those reasons remains valid now in my opinion. Regards Daniele
On Mon, Jun 30, 2025 at 3:36 AM Daniele Lupo via Boost < boost@lists.boost.org> wrote:
On 05/05/2025 23:45, Hassan Sajjad via Boost wrote:
Generally speaking your "benefits list" has quite bold statements
Are you proposing replacement of b2 for Boost or just yet another build system to the club?
These statements are based on concrete evidence. I am proposing to replace b2.
If I remember well, this is not the first time that you want to propose it, and I was against it for different reasons:
- We are already trying to replace the build system with cmake. - CMake can have pros and cons, but actually it's one of biggest standard in C++ development. Changing a "boost only" build system for another system that will used only for boost (I don't see hmake widely used) it's pretty useless.
Fwiw, I've made some good progress on this front and I've come up with this tool here: https://github.com/cmazakas/c2 This is a pure CMake b2-like runner for tests. Because it supports arbitrary CMake targets, it can be extended even for something like docs. - Christian

On Monday, June 30, 2025 at 16:42, Christian Mazakas via Boost < boost@lists.boost.org> wrote:
Fwiw, I've made some good progress on this front and I've come up with this tool here: ...
This is a pure CMake b2-like runner for tests.
Regarding c2, I wonder if ctest been ruled out? It integrates nicely with CMake and has its own test runner. Maybe it doesn't do everything you need or want, but perhaps it would be easy enough to enhance? High-level introduction: https://cmake.org/cmake/help/book/mastering-cmake/chapter/Testing%20With%20C... CTest module for CMake: https://cmake.org/cmake/help/latest/module/CTest.html Commandline test runner: https://cmake.org/cmake/help/latest/manual/ctest.1.html Matt
On Tue, Jul 1, 2025 at 11:23 AM Matt Gruenke via Boost < boost@lists.boost.org> wrote:
On Monday, June 30, 2025 at 16:42, Christian Mazakas via Boost < boost@lists.boost.org> wrote:
Fwiw, I've made some good progress on this front and I've come up with this tool here: ...
This is a pure CMake b2-like runner for tests.
Regarding c2, I wonder if ctest been ruled out? It integrates nicely with CMake and has its own test runner. Maybe it doesn't do everything you need or want, but perhaps it would be easy enough to enhance?
c2 dispatches to ctest to invoke everything. There's actually a couple of caveats with how I did things that are probably at least worth mentioning. But in general, c2 is just a glorified script that does: cmake .. && cmake --build . && ctest . Because of how I have to change some of the output ninja files, I inadvertently broke the compile-fail tests Peter's authored in BoostTest.cmake. I was able to fix it, by having c2 pass a c2-specific config variable that the Boost CMake could inspect and then use to do the correct thing. So far, I haven't run into any actual show-stoppers and it seems to work well for Boost. What's most important about the tool is that it lets you define your build matrix using a simple JSON file. And you can also specify a toolchain file per build variant directly. - Christian

Hi Hassan, 8) I wrote this paper
https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... . It is at most a 2-day work for a compile-dev to support this. This will allow 4x compilation speed improvement for Boost and even bigger gains for bigger projects.
Has this feature been implemented in any compiler? Upstreaming such a change to LLVM would demonstrate that it is mature enough to be used in production software and also provide a stamp of approval. It won't be easy to convince the community to switch to a new build system that requires modification to the C/C++ compiler. These are often unlikely to be adopted unless there is a significant demand for that feature in the community. Best, Marcin
9) HMake will support a feature called BigHu (described in previous email), which makes rebuilds incredibly fast as well. Also, I think header-units can be backported for older C++ versions as well, since they change semantics very little ( mostly around the preprocessor ). 10) HMake will also support https://lists.isocpp.org/sg15/2023/11/2146.php and https://lists.isocpp.org/sg15/2023/11/2106.php if these get implemented. 11) compile-commands.json support. HMake will generate these at configure time for the configurations being configured. 12) CMake integration support through CPS. Some features, like header-units might not work. 13) HMake will support multiple other programming languages, frameworks like iOS and Android app generation, different installers, etc.
HMake is still a novel build-system that is under heavy development. A project of Boost size using this in production will provide highly valuable insights that will tremendously improve the HMake itself as well. HMake is written in C++20, follows best practices, is extensively tested, uses TDD, and the core library is around 15k C++ lines.
I can also do a video call presentation of my software. This might be a quicker way to make yourself familiar with my software capabilities than reading documentation. Because I can do live examples and explain details accordingly.
Best, Hassan Sajjad
On Wed, Apr 16, 2025 at 5:21 PM Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
The interactions to reproduce the results.
https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp
On Wed, Apr 16, 2025, 16:34 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including
examples
and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
I have a solution for that. I am sending this paper (Making some final edits)
https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper...
, which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed.
My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it).
HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence.
The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get >3x faster compilation as well.
Best, Hassan Sajjad
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
Hi Marcin,
Has this feature been implemented in any compiler? Upstreaming such a change to LLVM would demonstrate that it is mature enough to be used in production software and also provide a stamp of approval.
Not yet. This is the next step. I can not add no-scanning build support without this, without which there can not be a useful drop-in header-units replacement. It won't be easy to convince the community to switch to a new build system
that requires modification to the C/C++ compiler. These are often unlikely to be adopted unless there is a significant demand for that feature in the community.
The changes required are minimal. Check the README in this repo https://github.com/HassanSajjad-302/ipc2978api. I also added small modifications to the paper. I am confident that Clang will accept the changes. Here is a comment from Clang dev and Tooling Study Group chair https://www.reddit.com/r/cpp/comments/1jb8acg/comment/mhvvfva/?utm_source=sh... I would also like to add that this isn't related to the design of modules.
Despite lots of claims, I have never seen a proposed design that would actually be any easier to implement in reality. You can make things easier by not supporting headers, but then no existing code can use it. You can also do a lot of things by restricting how they can be used, but then most projects would have to change (often in major ways) to use them. The fundamental problem is that C++ sits on 50+ years of textual inclusion and build system legacy, and modules requires changing that. There's no easy fix that's going to have high perf with a build system designed almost 50 years ago. Things like a module build server are the closest, but nobody is actually working on that from what I can tell.
Best, Hassan Sajjad On Tue, May 6, 2025 at 7:07 PM Marcin Copik <mcopik@gmail.com> wrote:
Hi Hassan,
8) I wrote this paper
https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... . It is at most a 2-day work for a compile-dev to support this. This will allow 4x compilation speed improvement for Boost and even bigger gains for bigger projects.
Has this feature been implemented in any compiler? Upstreaming such a change to LLVM would demonstrate that it is mature enough to be used in production software and also provide a stamp of approval.
It won't be easy to convince the community to switch to a new build system that requires modification to the C/C++ compiler. These are often unlikely to be adopted unless there is a significant demand for that feature in the community.
Best, Marcin
9) HMake will support a feature called BigHu (described in previous email), which makes rebuilds incredibly fast as well. Also, I think header-units can be backported for older C++ versions as well, since they change semantics very little ( mostly around the preprocessor ). 10) HMake will also support https://lists.isocpp.org/sg15/2023/11/2146.php and https://lists.isocpp.org/sg15/2023/11/2106.php if these get implemented. 11) compile-commands.json support. HMake will generate these at configure time for the configurations being configured. 12) CMake integration support through CPS. Some features, like header-units might not work. 13) HMake will support multiple other programming languages, frameworks like iOS and Android app generation, different installers, etc.
HMake is still a novel build-system that is under heavy development. A project of Boost size using this in production will provide highly valuable insights that will tremendously improve the HMake itself as well. HMake is written in C++20, follows best practices, is extensively tested, uses TDD, and the core library is around 15k C++ lines.
I can also do a video call presentation of my software. This might be a quicker way to make yourself familiar with my software capabilities than reading documentation. Because I can do live examples and explain details accordingly.
Best, Hassan Sajjad
On Wed, Apr 16, 2025 at 5:21 PM Hassan Sajjad <hassan.sajjad069@gmail.com
wrote:
The interactions to reproduce the results.
https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp
On Wed, Apr 16, 2025, 16:34 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including
examples
and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
I have a solution for that. I am sending this paper (Making some final edits)
https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper...
, which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed.
My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it).
HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence.
The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get 3x faster compilation as well.
Best, Hassan Sajjad
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
Hi Hassan, Hi Marcin,
Has this feature been implemented in any compiler? Upstreaming such a change to LLVM would demonstrate that it is mature enough to be used in production software and also provide a stamp of approval.
Not yet. This is the next step. I can not add no-scanning build support without this, without which there can not be a useful drop-in header-units replacement.
I'm not a Boost developer - only user - so I won't be able to comment on what this community will expect from your tool. However, as a potential user, I would be very wary of investing time in a tool that requires a custom and modified fork of an existing compiler. If you wanted to convince me, I would expect that you already have a fork of Clang that is up-to-date with the upstream, tested, and demonstrates the promised performance claims. Furthermore, I would hope to see initial discussions with LLVM developers that show (a) they are interested in this work and (b) they are open to merging it with the main distribution at some point.
It won't be easy to convince the community to switch to a new build system
that requires modification to the C/C++ compiler. These are often unlikely to be adopted unless there is a significant demand for that feature in the community.
The changes required are minimal.
Yes, I've seen several times the claim that the changes to the compiler are minimal and would require 1-2 days of work. If that is the case, then why not create a fork of Clang that shows it?
Check the README in this repo https://github.com/HassanSajjad-302/ipc2978api. I also added small modifications to the paper. I am confident that Clang will accept the changes. Here is a comment from Clang dev and Tooling Study Group chair https://www.reddit.com/r/cpp/comments/1jb8acg/comment/mhvvfva/?utm_source=sh...
I would also like to add that this isn't related to the design of modules.
Despite lots of claims, I have never seen a proposed design that would actually be any easier to implement in reality. You can make things easier by not supporting headers, but then no existing code can use it. You can also do a lot of things by restricting how they can be used, but then most projects would have to change (often in major ways) to use them. The fundamental problem is that C++ sits on 50+ years of textual inclusion and build system legacy, and modules requires changing that. There's no easy fix that's going to have high perf with a build system designed almost 50 years ago. Things like a module build server are the closest, but nobody is actually working on that from what I can tell.
I am not confident that Clang will accept such a change, and the provided comment seems unrelated to your proposal. Best, Marcin Best,
Hassan Sajjad
On Tue, May 6, 2025 at 7:07 PM Marcin Copik <mcopik@gmail.com> wrote:
Hi Hassan,
8) I wrote this paper
https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper... . It is at most a 2-day work for a compile-dev to support this. This will allow 4x compilation speed improvement for Boost and even bigger gains for bigger projects.
Has this feature been implemented in any compiler? Upstreaming such a change to LLVM would demonstrate that it is mature enough to be used in production software and also provide a stamp of approval.
It won't be easy to convince the community to switch to a new build system that requires modification to the C/C++ compiler. These are often unlikely to be adopted unless there is a significant demand for that feature in the community.
Best, Marcin
9) HMake will support a feature called BigHu (described in previous email), which makes rebuilds incredibly fast as well. Also, I think header-units can be backported for older C++ versions as well, since they change semantics very little ( mostly around the preprocessor ). 10) HMake will also support https://lists.isocpp.org/sg15/2023/11/2146.php and https://lists.isocpp.org/sg15/2023/11/2106.php if these get implemented. 11) compile-commands.json support. HMake will generate these at configure time for the configurations being configured. 12) CMake integration support through CPS. Some features, like header-units might not work. 13) HMake will support multiple other programming languages, frameworks like iOS and Android app generation, different installers, etc.
HMake is still a novel build-system that is under heavy development. A project of Boost size using this in production will provide highly valuable insights that will tremendously improve the HMake itself as well. HMake is written in C++20, follows best practices, is extensively tested, uses TDD, and the core library is around 15k C++ lines.
I can also do a video call presentation of my software. This might be a quicker way to make yourself familiar with my software capabilities than reading documentation. Because I can do live examples and explain details accordingly.
Best, Hassan Sajjad
On Wed, Apr 16, 2025 at 5:21 PM Hassan Sajjad < hassan.sajjad069@gmail.com> wrote:
The interactions to reproduce the results.
https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp
On Wed, Apr 16, 2025, 16:34 Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including
examples
and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
I have a solution for that. I am sending this paper (Making some final edits)
https://htmlpreview.github.io/?https://github.com/HassanSajjad-302/iso-paper...
, which allows for a build-system to use a scanning-less approach to build header-units.This method requires only minimal modifications to the compiler and enables memory-mapped file sharing, which significantly reduces filesystem overhead and further boosts speed.
My proposal for a scanning-less approach will allow HMake to have another amazing feature, monolithic Big header-units. BigHu will allow you to map all the headers from a directory to a single header-unit. This header-unit includes all these header-files and consumes them as header-files. Now, whenever the compiler requests a header-unit from this directory, the build-system instead sends this consolidated BigHu. This will not only improve the clean build speed, because of fewer process launches. But also massively boosts the rebuild speed as few header-units need to be read instead of lots of files. No source-code editing will be needed to use this feature. And you will have the option to either build a library as BigHu (if you don't mean to edit it) or as small header-units (if you are working on it).
HMake will soon support compile_commands.json, which I guess can work fine with header-units. Thus you can benefit from both, faster compilation and working intelliscence.
The API shown in hmake.cpp is a work in progress. HMake build-system benefits are numerous, even if we leave out the header-units support. This makes it a perfect replacement for B2. I believe we can complete the switch in the next 2 months. And if some compiler supports my paper, we get 3x faster compilation as well.
Best, Hassan Sajjad
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost

CMake is very "unsafe" build system. CMake often break compatability and make many problem on stable server systems like Debian, RHEL, CentOS and etc, where CMake is too old alltime. I think CMake may be alternative build sytem, but not common. -- wbr, Leonid

Too old... well at least its available. And if you're ready to install another build system, you may as well install a recent CMake. ---- Alain Miniussi DSI, Pôles Calcul et Genie Log. Observatoire de la Côte d'Azur Tél. : +33609650665 ----- On Jun 30, 2025, at 1:24 PM, cppleo--- via Boost boost@lists.boost.org wrote:
CMake is very "unsafe" build system. CMake often break compatability and make many problem on stable server systems like Debian, RHEL, CentOS and etc, where CMake is too old alltime.
I think CMake may be alternative build sytem, but not common.
-- wbr, Leonid _______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/Q33SW4HV...
wt., 1 lip 2025 o 14:21 cppleo--- via Boost <boost@lists.boost.org> napisał(a):
CMake is very "unsafe" build system. CMake often break compatability and make many problem on stable server systems like Debian, RHEL, CentOS and etc, where CMake is too old alltime.
I think CMake may be alternative build sytem, but not common.
CMake has a convenient system of binary releases that are easy to install without requiring root permissions. Updating CMake to the latest version is rather straightforward, even on HPC clusters that often run ancient software. Best, Marcin
-- wbr, Leonid _______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/Q33SW4HV...
Latest Release (4.0.3): Binary distributions: Windows x64 Installer: Windows x64 ZIP Windows i386 Installer: Windows i386 ZIP Windows ARM64 Installer: Windows ARM64 ZIP macOS 10.13 or later macOS 10.10 or later Linux x86_64 Linux aarch64 SunOS sparc64 SunOS x86_64 Is that all? Where is FreeBSD binaries? Where is NetBSD binaries? Where is non-x86 and non-ARM binraies for Linux? What about legacy systems works on factories (Windows 2000, OS/2 (ArcaOS))? The FreeBSD is very popular server OS. Legacy systems will continue work. If you ignore them, they ignore you. (How do you think what is chipper: halt a rolling mill or keep use legacy system with Windows NT 4.0, Windows 2000, OS/2, Novell NetWare, etc?) Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation. If Boost break building via b2 (non-CMake), Boost will damage reputation again. -- wbr, Leonid

I'm confused, where can people download B2 binaries? On Jul 1, 2025 11:52 AM, cppleo--- via Boost <boost@lists.boost.org> wrote: Latest Release (4.0.3): Binary distributions: Windows x64 Installer: Windows x64 ZIP Windows i386 Installer: Windows i386 ZIP Windows ARM64 Installer: Windows ARM64 ZIP macOS 10.13 or later macOS 10.10 or later Linux x86_64 Linux aarch64 SunOS sparc64 SunOS x86_64 Is that all? Where is FreeBSD binaries? Where is NetBSD binaries? Where is non-x86 and non-ARM binraies for Linux? What about legacy systems works on factories (Windows 2000, OS/2 (ArcaOS))? The FreeBSD is very popular server OS. Legacy systems will continue work. If you ignore them, they ignore you. (How do you think what is chipper: halt a rolling mill or keep use legacy system with Windows NT 4.0, Windows 2000, OS/2, Novell NetWare, etc?) Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation. If Boost break building via b2 (non-CMake), Boost will damage reputation again. -- wbr, Leonid _______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/TQ3QIDYD...
On Tue, Jul 1, 2025 at 10:52 AM cppleo--- via Boost <boost@lists.boost.org> wrote:
Legacy systems will continue work. If you ignore them, they ignore you. (How do you think what is chipper: halt a rolling mill or keep use legacy system with Windows NT 4.0, Windows 2000, OS/2, Novell NetWare, etc?)
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation. If Boost break building via b2 (non-CMake), Boost will damage reputation again.
Also, I'd like to see some citations for this. As for Asio, that's just what Asio does. Asio breaks every few releases because the author just changes the code to be what he thinks is best. Interestingly, in my experience, frozen toolchains include frozen _everything_, including libraries. I really don't believe there's a company rolling a frozen C++03 gcc-4.8 toolchain using bleeding-edge Boost but maybe I'm wrong. What's more, I don't think anyone in this position would think less of Boost or think of it as tarnishing its reputation. - Christian

On 02/07/2025 17:04, Christian Mazakas via Boost wrote:
On Tue, Jul 1, 2025 at 10:52 AM cppleo--- via Boost <boost@lists.boost.org> wrote:
Legacy systems will continue work. If you ignore them, they ignore you. (How do you think what is chipper: halt a rolling mill or keep use legacy system with Windows NT 4.0, Windows 2000, OS/2, Novell NetWare, etc?)
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation. If Boost break building via b2 (non-CMake), Boost will damage reputation again.
Also, I'd like to see some citations for this. At least for Math and Multiprecision, I don't think think we have ever had a bug report submitted asking us to reinstate C++03 (or even C++11) support. On the other hand we pretty consistently get reports from folks using bleeding edge features and compilers, and (rightly) complaining when they don't work. It's actually surprising how much stuff has been broken by new C++ standards: it's mostly things getting marked as deprecated (float_denorm_style is the next one for us to sort out), but there were changes to the preprocessor for C++23 which have hit us too.
On a practical note, it's simply not feasible to support every possible language standard, and certainly not possible for a larger library to rigorously CI them all. Best, John.
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation.
[Sarcasm ON] As it was not broken long ago. Honestly since C++11 boost become far less essential [Sarcasm OFF] Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
If Boost break building via b2 (non-CMake), Boost will damage reputation again.
[Sarcasm ON] I don't think anybody but Boost maintainers will notices [Sarcasm Off] Artyom
On 07/07/2025 14:45, Artyom Beilis via Boost wrote:
Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
I've said this many times. This should not be an issue. Every library at some point breaks with the past and go ahead, for many reason, maintanance, readability etc... And for that reason we also have the X.Y.Z version numbering where - Z: number updated when there are minor bugfixes but no API changes - Y: number updated when there are API changes and updated of the featured but maintaining API compatibility - X: number updated when there are API changes that make the library not compatible with previous versions. It's true that there's a lot of legacy code that uses boost and cannot be upgraded to new compilers or standards, but it's also true that they can remain stuck with their own boost version, the one that works. In my opinion at some point it will be necessary to break compatibility with old standards and compilers, update boost, remove old legacy code that at this point will be useless and start Boost 2.0. Users of old versions can use the 1.Y.Z version of boost, they don't stop working because a new version is out, and it's possible to decide a maintanance period of time, i.e. one year, for which we can release 1.Y.ZZ versions that fixes bugs in this main branch of boost, if needed. It's not different from about many other companies do with their libraries, and this will allow a migration to a more efficient boost that must do not handle a lot of compilers and standards and architectures, and maintain the old version for an amount of time that we can decide.
If Boost break building via b2 (non-CMake), Boost will damage reputation again. [Sarcasm ON] I don't think anybody but Boost maintainers will notices [Sarcasm Off]
Maybe. A lot of people uses b2 for building boost, instead of using vcpkg, conan and so on. Daniele
On Mon, Jul 7, 2025 at 4:00 PM Daniele Lupo via Boost <boost@lists.boost.org> wrote:
On 07/07/2025 14:45, Artyom Beilis via Boost wrote:
Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
I've said this many times. This should not be an issue. Every library at some point breaks with the past and go ahead, for many reason, maintanance, readability etc... And for that reason we also have the X.Y.Z version numbering where
True but Boost have never followed this. The major version = 1.XX and rest are never handled. What would be the correct solution is something like Boost.LTS 2. That would carry API and ABI stable for years to come and release minor updates and anything that breaks goes to next version till it is released after YEARS not few months. And the rest of the updates are backward API/ABI compatible. It is very hard to use Boost in any large scale project without something like that. Most large C++ libraries manage it. Don't see why Boost Can't/ Maybe there should be a Core Boost functionality that stabilized and maintained this way. I remember back in the days when I started CppCMS Boost was a huge headache and I needed to create a stable fork of some highly needed libraries to keep the API/ABI stable. But anyhow Boost to me had become a playground of some cool ideas that some of them become legend (shared_ptr, regex, etc) It Bootstrapped C++11 but for long term projects Boost nowadays isn't very useful. Artyom

It Bootstrapped C++11 but for long term projects Boost nowadays isn't very useful.
Since this was with respect to keeping things ABI stable. In my view, boost accepting ABI breakage is the very reason that it stays relevant. The standard library for some popular compilers are stuck in the past while there are known improvements which are not implemented due to ABI stability. This makes the standard library way less useful for long-term projects, since its known that they will never improve, or even fix issues in case it potentially changes the ABI. See for example std regex or std unordered map. Boost implementing improvements regardless of ABI is one of the great things with Boost.

On Monday, July 7, 2025 14:06, Jakob Lövhall wrote:
Since this was with respect to keeping things ABI stable. In my view, boost accepting ABI breakage is the very reason that it stays relevant.
Just out of curiosity: are you developing on Windows or Linux? For Linux devs, the issue is that if we link in some 3rd library supplied by the distro, and it happens to link in some Boost libs, then we must either take the distro version of Boost for our own code, rebuild the other distro-provided libraries we want to use that link in Boost, or just avoid the mess and forego using Boost in our code. I'd bet most of you have run into people or projects that make a concerted effort to avoid using Boost, and I'm sure that's one of the reasons. ABI compatibility is indeed a high bar, but I see value in at least trying to manage when the breaking changes happen. Not that I'd expect Boost to change now, but just wanted to share my experience with the matter. Matt
Just out of curiosity: are you developing on Windows or Linux?
Linux
ABI compatibility is indeed a high bar, It is more like a fence, or wall, blocking improvement imho.
Sure sometimes libraries are built with a earlier version that one would like. It sucks to be on that earlier version when its known that there is some dope feature in a newer version. But, then sure, be stuck on that earlier version. Then you get all the functionality from that version, but on the other hand, at some point in the future, dependencies could update and you get improvements. With ABI stability you could upgrade right away (if the issue is specifically dynamic linkage to targets with non hidden symbols), but pay the cost of not having the same improvements. Jakob
On Monday, July 7, 2025 3:40 PM, Jakob Lövhall wrote:
It is more like a fence, or wall, blocking improvement imho.
It doesn't block all improvements, nor would I envision a scenario where strict ABI compatibility is required over an extended range of releases. I merely suggested that ABI-breaking changes might be managed in some way, rather than being completely ad hoc. One way they could be managed is with versioned namespaces. Another way would be to adhere to proper semantic versioning and then space out the releases with ABI and API -breakage a little more.
Sure sometimes libraries are built with a earlier version that one would like. It sucks to be on that earlier version when its known that there is some dope feature in a newer version.
I think we're mostly saying the same thing, here. If ABI-incompatible versions of Boost were fewer and farther in between, then you could usually upgrade to a newer version of Boost and utilize some newer features, even when linking against some 3rd libraries that also use Boost. They wouldn't hold you back so strictly, like they do today.
at some point in the future, dependencies could update and you get improvements.
Distros try to avoid incompatible library dependency changes, [i]precisely because[/i] they can ripple through library dependency chains like a bunch of dominos. The exceptions are when you're on a rolling-release distro or you perform a wholesale upgrade of a stable distro.
With ABI stability you could upgrade right away (if the issue is specifically dynamic linkage to targets with non hidden symbols), but pay the cost of not having the same improvements.
Right. You'd be limited in the nature and extent of improvements you could attain, without jumping to a new major version. I do wonder how often ABI-incompatible changes are really necessary. There's also an uncounted benefit, which is the potential for more libraries (esp. open source) to use Boost, if some of the current downsides of doing so were mitigated. Unfortunately, I think that ship has pretty much sailed. Matt -----Original Message----- From: Jakob Lövhall <lovhall@protonmail.com> Sent: Monday, July 7, 2025 3:40 PM To: Boost developers' mailing list <boost@lists.boost.org> Cc: Matt Gruenke <mgruenke@tycoint.com> Subject: Re: [boost] Re: API Stability (was: A proposal for a modern build-system_
Just out of curiosity: are you developing on Windows or Linux?
Linux
ABI compatibility is indeed a high bar, It is more like a fence, or wall, blocking improvement imho.
Sure sometimes libraries are built with a earlier version that one would like. It sucks to be on that earlier version when its known that there is some dope feature in a newer version. But, then sure, be stuck on that earlier version. Then you get all the functionality from that version, but on the other hand, at some point in the future, dependencies could update and you get improvements. With ABI stability you could upgrade right away (if the issue is specifically dynamic linkage to targets with non hidden symbols), but pay the cost of not having the same improvements. Jakob
Matt Gruenke wrote:
On Monday, July 7, 2025 3:40 PM, Jakob Lövhall wrote:
It is more like a fence, or wall, blocking improvement imho.
It doesn't block all improvements, nor would I envision a scenario where strict ABI compatibility is required over an extended range of releases. I merely suggested that ABI-breaking changes might be managed in some way, rather than being completely ad hoc.
That's completely impractical for Boost. Managing ABI-breaking changes in some way, in any way, is not just a matter of saying so. It's exceedingly hard. Even knowing, to a reasonable degree of certainty, whether there was an ABI break would be very hard for us because it would require test infrastructure we don't currently have, to be managed by people we don't currently have. And that's even without taking into account things like, say, the result of mp_unique<mp_list<int, float, int>> changing from mp_list<int, float> to mp_list<float, int> being potentially an ABI break. There's no ABI here anywhere, right? mp11 is purely compile time. And yet, if a type changes from X<int, float> to X<float, int> as a result, you'd have a potential ABI break somewhere, far removed from the mp11 change.
On Mon, Jul 7, 2025 at 11:51 AM Matt Gruenke via Boost < boost@lists.boost.org> wrote:
On Monday, July 7, 2025 14:06, Jakob Lövhall wrote:
Since this was with respect to keeping things ABI stable. In my view, boost accepting ABI breakage is the very reason that it stays relevant.
Just out of curiosity: are you developing on Windows or Linux? For Linux devs, the issue is that if we link in some 3rd library supplied by the distro, and it happens to link in some Boost libs, then we must either take the distro version of Boost for our own code, rebuild the other distro-provided libraries we want to use that link in Boost, or just avoid the mess and forego using Boost in our code.
I'd bet most of you have run into people or projects that make a concerted effort to avoid using Boost, and I'm sure that's one of the reasons.
ABI compatibility is indeed a high bar, but I see value in at least trying to manage when the breaking changes happen. Not that I'd expect Boost to change now, but just wanted to share my experience with the matter.
Isn't this overcome by just statically linking in the Boost code you need specifically and then making sure none of the symbols are publicly visible? - Christian
On Monday, July 7, 2025 6:51 PM, Christian Mazakas wrote:
Isn't this overcome by just statically linking in the Boost code you need specifically and then making sure none of the symbols are publicly visible?
If the 3rd library uses boost datatypes in its public interface, then there's no way around having to ensure both are compiled against versions of boost that are mutually compatible in the layout and semantics of these data types. To do otherwise is an ODR violation, no matter what kind of linkage they use. Right here, this provides an argument to care about managing ABI breakage. An interesting case study on how to handle such ABI changes is libstdc++'s concurrent support for STL datatypes both before and after the changes introduced by C++11, which involved relegating the legacy versions to their own C++ namespace (see: https://gcc.gnu.org/onlinedocs/libstdc++/manual/using_dual_abi.html ). If we're merely concerned about incidental boost symbol collisions, then static linkage might indeed be a workaround. However, it has the downside that whenever a bug or security vulnerability -fixed build of the boost version used by your code is released, you must also release a new build. Whereas, a benefit of shared libraries is that the distro could release a fixed build of the boost version you used and the end user benefits without you having to release a new build of your app or the user having to install it. Now, you might wonder how we might simultaneously worry about boost version inconsistencies while still relying on the distro to provide security updates. One distro I use is currently tracking two boost releases, while another is tracking three. So, even sticking with a distro-provided boost, there are still opportunities for inconsistencies to arise relative to what other distro-provided libraries use. This isn't my area of expertise, but a workaround for incidental shared library symbol collisions appears to exist in the form of ELF symbol versioning. I think this could enable multiple versions of boost to be linked into the same executable, without the symbols from one overriding any symbols from the other. If my understanding is correct, this could provide the benefits you sought from static linking, without foregoing the maintenance advantages of dynamic linking. Not that it would alleviate most of the issues stemming from ABI instability, but I think it would address some cases. Matt
This isn't my area of expertise, but a workaround for incidental shared library symbol collisions appears to exist in the form of ELF symbol versioning. I think this could enable multiple versions of boost to be linked into the same executable, without the symbols from one overriding any symbols from the other. If my understanding is correct, this could provide the benefits you sought from static linking, without foregoing the maintenance advantages of dynamic linking. Not that it would alleviate most of the issues stemming from ABI instability, but I think it would address some cases.
This is easier to do at the source code level by placing exported symbols in a detail namespace whose name is mangled with the Boost version: this is what regex does, and I suspect other libraries too. It has the side effect of reducing support requests from people who accidentally try and link to the wrong library version, as well as allowing to different versions to co-exist. John.

On Mon, Jul 7, 2025 at 6:41 AM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
It Bootstrapped C++11 but for long term projects Boost nowadays isn't very useful.
This is false. Boost is very useful and becoming more so with every release, in no small part thanks to the continual evolution of its flagship libraries such as Asio and also for the new libraries which have innovated beyond the standard library such as Boost.Unordered, Boost.Hash2, Boost.Bloom. Many such examples exist. Contrary to your point, Boost is more useful than ever and fills in the growing number of gaps left open by the C++ Standard. "The C++ Standard Library cannot connect to the Internet." - Vinnie Falco Thanks

In article <CAOsONKz8s8OvWQE09xceK6w9J=zhW=sR2Hbqu0=AAeZDWOYAqw@mail.gmail.com>, "Artyom Beilis via Boost" <boost@lists.boost.org> writes:
It is very hard to use Boost in any large scale project without something like that.
You have all the sources and a permissive license. You can hire an engineer to modify the last version of boost libraries you find acceptable as an ABI compatible baseline to incorporate whatever improvements you desire under the constraints you require. In other words, there is no barrier that prevents you from doing what you want to do. Considering the cost of creating boost libraries from scratch that were provided to anyone at no cost with no restrictive licening, paying someone to make improvements on top of such a foundation is an amazing bargain. So I guess I don't understand the problem. -- Richard -- "The Direct3D Graphics Pipeline" free book <http://tinyurl.com/d3d-pipeline> The Terminals Wiki <http://terminals-wiki.org> The Computer Graphics Museum <http://ComputerGraphicsMuseum.org> Legalize Adulthood! (my blog) <http://LegalizeAdulthood.wordpress.com>
On 07/07/2025 15:40, Artyom Beilis via Boost wrote:
On Mon, Jul 7, 2025 at 4:00 PM Daniele Lupo via Boost <boost@lists.boost.org> wrote:
On 07/07/2025 14:45, Artyom Beilis via Boost wrote: I've said this many times. This should not be an issue. Every library at some point breaks with the past and go ahead, for many reason, maintanance, readability etc... And for that reason we also have the X.Y.Z version numbering where
True but Boost have never followed this. The major version = 1.XX and rest are never handled.
What would be the correct solution is something like Boost.LTS 2.
That would carry API and ABI stable for years to come and release minor updates and anything that breaks goes to next version till it is released after YEARS not few months.
And the rest of the updates are backward API/ABI compatible.
ABI compatibility is a delicate matter. Yes, I agree that for some long-term project it can be helpful, but it can also limit the development of libraries a lot. We all know about std::regex and its limits due to the fact that it needs to maintain ABI compatibility. It's a tradeoff between stability and agility in implementing new features (or simply fixing bugs); maintaing ABI compatibility make those process far more complicated, and I'm personally against things lime PIMPL like Qt does, but remember, it's my personal opinion, it does not count in a community decision. My feeling is that in Boost API are more important that ABI; if you download the new version of boost is because you want to use it in your project, and since many boost libraries are header-only, in order to use boost you need to rebuild the project. Sure, you can link your project to another legacy one that cannot be recompiled, but in that case you can stay with your current version of Boost, or the boost community can ensure that X.Y.Z version of boost libraries maintains the same ABI for every patch version (X, Y remains the same, Z is updated). It's possible to maintain a rule that say - Patch version update: ABI compatibility guaranteed - Minor version update: API compatibility guaranteed - Major version update: Some API is broken (you can need to change your code) As I've said before, I'm not a huge fan of ABI compatibility, probably because it's not important in my work, but if it's important for many developers we can decide something like that. Anyway I think that about it Boost community should make some discussion and decision, then take the decision and use them for create the Boost 2.0, where those decisions became the guidelines for developing of new libraries.
And the rest of the updates are backward API/ABI compatible.
ABI compatibility is a delicate matter. Yes, I agree that for some long-term project it can be helpful, but it can also limit the development of libraries a lot. We all know about std::regex and its limits due to the fact that it needs to maintain ABI compatibility.
There are lots of ways to handle ABI compatibility (Qt's d-pointer is classic) But we are not even in an API area. API is broken virtually every release. It is a huge problem for a long running project especially when you have no idea what version of Boost you are going to be linked with. I would accept at least API stability - but it does not exist. Artyom
On Tue, Jul 8, 2025 at 9:34 AM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
And the rest of the updates are backward API/ABI compatible.
ABI compatibility is a delicate matter. Yes, I agree that for some long-term project it can be helpful, but it can also limit the development of libraries a lot. We all know about std::regex and its limits due to the fact that it needs to maintain ABI compatibility.
There are lots of ways to handle ABI compatibility (Qt's d-pointer is classic)
But we are not even in an API area. API is broken virtually every release.
It is a huge problem for a long running project especially when you have no idea what version of Boost you are going to be linked with.
Can you point to concrete projects where that has been a problem? As it's hard to discuss these things in the abstract. -- -- René Ferdinand Rivera Morell -- Don't Assume Anything -- No Supongas Nada -- Robot Dreams - http://robot-dreams.net
Can you point to concrete projects where that has been a problem? As it's hard to discuss these things in the abstract.
Ok... Here is an example I encountered just yesterday. I needed to provide a fork/exec/kill/wait alternative for Windows... I know the boost proces - Ok - header only library - fantastic. Until now my project didn't use boost so I get the latest version. So quick google (and their gemeni) leads to examples exactly what I need: bp::child, wait, terminate, wait_for etc. Lots of tutorials fine. I write the code down and... it wouldn't compile... Ok look at the latest API it changed. Deep down it happened at v1.86 about a year ago. But not a simple change - wipe out an old API and create a new API... Not add (bp::process) - remove child and replace it with process! If I was using the boost process in the first place when I started the project instead of fork/exec and then later ported it to windows I would discover that the code stopped working with the latest release. More than that most linux distros wouldn't even ship 1.86 so I need either require a specific boost version or tell use the old one. No grace time, no deprecation, no keeping old API for a while (replacing headers with v1 is not backward compatibility it is a workaround) And honestly including huge dependency on Boost.Asio without "asking" is a problem. It just reminded me why I avoid using Boost in my own projects! If I had been using Boost.Process it would break while porting to Windows. And I ended up skipping on the Boost once again instead of using boost.process I just kept my fork/exec/kill/wait code and added win32 version of CreateProcess/Terminate/GetExistStatus - it was way simpler than deal with multiple APIs. And this isn't my first such experience, it just reminded me why I ditched Boost for my projects in the first place and probably not looking back unless I absolutely must. Artyom
I write the code down and... it wouldn't compile... Ok look at the latest API it changed. Deep down it happened at v1.86 about a year ago.
Actually looking deeper into to https://github.com/boostorg/process/issues/480 It seems that v2 was introduced in 1.86 and v1 API (like child and apparently groups) was removed in 1.88 Removing the API unless it poses a security risk isn't acceptable by any means. A small decision by one developer can affect hundreds and even thouthands of projects and lead to huge amounts of work for Boost users all around the globe. And Boost.Process is just an example. I mean I didn't even have to dig - it was the first Boost library I touched for years and it once again showed me exactly the reason I ditched Boost in the first place. If I wasn't an experienced developer I'd probably bite the bullet and add ifdefs etc, but for me it was obvious not to use Boost as it brings more headache than solves problems. Regards, Artyom I touche
On Thu, Jul 31, 2025 at 12:59 AM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
...it brings more headache than solves problems.
Given that many individuals and organizations using Boost do not develop headaches I would surmise that Boost itself is not the sole cause of said headaches. Thanks
On Thu, Jul 31, 2025 at 12:43 PM Vinnie Falco <vinnie.falco@gmail.com> wrote:
On Thu, Jul 31, 2025 at 12:59 AM Artyom Beilis via Boost <boost@lists.boost.org> wrote:
...it brings more headache than solves problems.
Given that many individuals and organizations using Boost do not develop headaches I would surmise that Boost itself is not the sole cause of said headaches.
Thanks
Ok I've seen several organizations that used Boost heavily in their code base and... had huge headaches. What happened since it was an internal project/product they just were stuck with some old version of boost. They couldn't upgrade because it broke huge amount of their code and they couldn't get some essential updates because there were stuck I also observed several cases when upgrading Boost was a major event that was breaking lots of code and required careful management. So, it is a real headache. There are always headaches when upgrading some toolkits (like Qt, and others) but boost takes it to an absolutely next level - because nothing is in sync. Now this is about organizations that release their own product, with their own version. So it is a relatively simple case. When we are talking about library or open-source projects that can be built on a very large number of platforms and versions it becomes virtually impossible to use boost intensively because there will be a very large gap in versions that is virtually impossible to close. An only alternative is to use private stipped version of Boost with renamed namespace (to prevent ABI clash with user's boost) I love that Boost gives lots of tools of a good quality and easy to use but sometimes I wish it was actually usable in any long term project. So sorry to break it to you, but It is a _big_ problem. Artyom Beilis
On Wed, Jul 30, 2025 at 11:54 PM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
I write the code down and... it wouldn't compile... Ok look at the latest API it changed. Deep down it happened at v1.86 about a year ago.
The tendency for a library's API to break will vary, as each Boost library has its own set of authors and/or maintainers. Thanks
On Thu, Jul 31, 2025 at 12:40 PM Vinnie Falco <vinnie.falco@gmail.com> wrote:
On Wed, Jul 30, 2025 at 11:54 PM Artyom Beilis via Boost <boost@lists.boost.org> wrote:
I write the code down and... it wouldn't compile... Ok look at the latest API it changed. Deep down it happened at v1.86 about a year ago.
The tendency for a library's API to break will vary, as each Boost library has its own set of authors and/or maintainers.
Thanks
Yes, this is why policies are useful. Boost has 1001 difference policies and restrictions on libraries but 0 requirements on any kind of compatibility/stability. These kinds of issues must be addressed by policies and management of something like a Long Term Support version that would keep the API stable for at least several years. Artyom

I'm replying to this as someone who has used the old and new versions of Boost Process API. And migrated code (not hard) to the new API. And left code that I haven't had reason to update, using the old version of Boost, with the old API. On Thu, 31 July 2025, 8:36 pm Artyom Beilis via Boost, < boost@lists.boost.org> wrote:
On Thu, Jul 31, 2025 at 12:40 PM Vinnie Falco <vinnie.falco@gmail.com> wrote:
On Wed, Jul 30, 2025 at 11:54 PM Artyom Beilis via Boost <
boost@lists.boost.org> wrote:
I write the code down and... it wouldn't compile... Ok look at the latest API it changed. Deep down it happened at v1.86 about a year ago.
The tendency for a library's API to break will vary, as each Boost library has its own set of authors and/or maintainers.
Thanks
Yes, this is why policies are useful.
Boost has 1001 difference policies and restrictions on libraries but 0 requirements on any kind of compatibility/stability.
This is good. It lets the user chose (to stay in an old version or pick a newer one). I trust Boost authors not to gratuitously change APIs.
These kinds of issues must be addressed by policies and management of something like a Long Term Support version that would keep the API stable for at least several years.
A policy won't force a volunteer author or maintainer to provide support for anything, especially not an API said author considers flawed. If you want paid (so one might expect, policy conforming) support for stable APIs I can recommend some vendors that give me far more expensive headaches than Boost does. Or you can, as I do, carry the cost of managing versions / update policy regarding use of Boost libraries yourself. Just another perspective as a long term Boost user. As always, YMMV. Darryl.
On Thu, Jul 31, 2025 at 2:17 PM Darryl Green via Boost <boost@lists.boost.org> wrote:
I'm replying to this as someone who has used the old and new versions of Boost Process API. And migrated code (not hard) to the new API. And left code that I haven't had reason to update, using the old version of Boost, with the old API.
It isn't a question if it is hard or not... Most of the breaking so far was possible to fix this way or other. The questions are - Why do you need to _remove_ the API that hundreds of projects depend on? - How are users supposed to manage building against different incompatible versions of Boost? Artyom

On Thu, Jul 31, 2025 at 7:46 PM Artyom Beilis via Boost < boost@lists.boost.org> wrote:
On Thu, Jul 31, 2025 at 2:17 PM Darryl Green via Boost <boost@lists.boost.org> wrote:
I'm replying to this as someone who has used the old and new versions of Boost Process API. And migrated code (not hard) to the new API. And left code that I haven't had reason to update, using the old version of Boost, with the old API.
It isn't a question if it is hard or not... Most of the breaking so far was possible to fix this way or other.
The questions are
- Why do you need to _remove_ the API that hundreds of projects depend on?
It was not removed. The headers were moved into a v1 subfolder, and the content into a v1 namespace that can be inlined by defined BOOST_PROCESS_VERSION =1. So the required code refactor is replacing every instance `#include <boost/process`with `#include <boost/process/v1`. Security was among the reasons I decided to make v2 the default.
Artyom _______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/ASA7IOAY...
On Thu, 31 July 2025, 9:47 pm Artyom Beilis via Boost, < boost@lists.boost.org> wrote:
It isn't a question if it is hard or not... Most of the breaking so far was possible to fix this way or other.
Isn't it? You are asking Boost to somehow force maintainers to do something by having a policy of maintaining API stability. I'm just saying I'm good with current (lack of) that policy, and why.
The questions are
- Why do you need to _remove_ the API that hundreds of projects depend on?
It isn't removed (I can still use it). It is still available in the last version that supported that API. - How are users supposed to manage building against different
incompatible versions of Boost?
However they like. Try not to (use multiple) is my go-to answer. The reality is API breaking changes are rare. One way to deal with hard problems is to go around them. I would note modular boost helps re picking and choosing libraries and hence library versions.
Isn't it? You are asking Boost to somehow force maintainers to do something by having a policy of maintaining API stability. I'm just saying I'm good with current (lack of) that policy, and why.
Two points 1. There is already a policy for example there are times when you can introduce breaking changes, but it happens like very few months 2. From a maintainer POV, obviously less rules is better, but what I'm talking about is a user POV.
I would note modular boost helps re picking and choosing libraries and hence library versions.
Once again it is OK if you copy for example a private copy of boost for you and use it internally. It is almost never the case for open-source projects. Best, Artyom

On Sun, Aug 3, 2025, at 10:54 AM, Artyom Beilis via Boost wrote:
Once again it is OK if you copy for example a private copy of boost for you and use it internally. It is almost never the case for open-source projects.
It is where I live. I only use e.g. FetchContent, download the tarball or using Nix flakes. Not an inch of pain. Just document which version of boost is supported. If you're concerned about users not able to deploy somewhere in a convenient way (e.g. without Nix or containers) you can always supply the option of static linking. External dependencies are the pain, I don't see any way in which Boost is special. I've had commercial projects relying on 50-100 external tools and libraries (it was in digital forensics) and Boost certainly wasn't the worst to deal with. Just my $0.02
We need someone to make a TikTok video showing how easy it is to install just what you need from Boost, and get going with a working `main` in minutes. Thanks On Sun, Aug 3, 2025 at 9:42 AM Seth via Boost <boost@lists.boost.org> wrote:
On Sun, Aug 3, 2025, at 10:54 AM, Artyom Beilis via Boost wrote:
Once again it is OK if you copy for example a private copy of boost for you and use it internally. It is almost never the case for open-source projects.
It is where I live. I only use e.g. FetchContent, download the tarball or using Nix flakes. Not an inch of pain. Just document which version of boost is supported. If you're concerned about users not able to deploy somewhere in a convenient way (e.g. without Nix or containers) you can always supply the option of static linking.
External dependencies are the pain, I don't see any way in which Boost is special. I've had commercial projects relying on 50-100 external tools and libraries (it was in digital forensics) and Boost certainly wasn't the worst to deal with.
Just my $0.02 _______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/7DPDBSYG...
-- Regards, Vinnie Follow me on GitHub: https://github.com/vinniefalco
External dependencies are the pain, I don't see any way in which Boost is special. I've had commercial projects relying on 50-100 external tools and libraries (it was in digital forensics) and Boost certainly wasn't the worst to deal with.
I honestly hope that Boost aims for something better than not the worst library to deal with It just clearly shows how broken the situation is. Bottom line. While Boost is a fantastic project, it can really be a nightmare for long running projects and there are a huge number of examples. So instead of covering it with "it is the Boost way" or "you can manage by putting it all into a container" and other "workarounds" What is needed is fixing the policies and creating some LTS versions... I don't understand how it isn't the _obvious_ thing for any SW developer. My $0.02 Artyom

Hi Artyom, You raise fair points and valid concerns — Boost is a powerful project, but precisely because of its scope and depth, it comes with real challenges when used in long-term or production-critical environments. If I were to summarize your points: - There's a lack of API/ABI stability - No clear LTS versions - Frequent internal changes that make maintenance difficult over time If those things don’t exist yet, it’s likely not just oversight. As others have mentioned, Boost is largely maintained by volunteers — people working on their own time, without funding. Given the scale and decentralized nature of Boost, aligning on policies, release cycles, and long-term guarantees is no small task — and I have no doubt that for decades now maintainers have been doing their best with the time and resources at their disposal. Still, that doesn’t mean we can’t work toward a better state. There’s likely room for a more pragmatic middle ground. One practical idea would be to identify and curate a stable subset of Boost — libraries that are very mature, very stable, and widely adopted in industry. Just having a baseline like this could help reduce friction for teams that need reliability across long software lifecycles. Of course, a counterpoint is that Boost’s peer-review process is already strict and demanding, and formalizing a “stable subset” might be seen as creating second-class citizens within the ecosystem. But it could just remain informal/informative. So even without changing Boost’s internal policies, I believe the first step should be at least to gather real-world data on API stability and user experience — that would at least help guide future decisions based on actual usage and pain points. It could be valuable to start collecting both maintainer and user feedback: - Which Boost components are most painful to maintain versus to use ? - Which APIs feel solid versus which evolve often? - What would help users most versus what would deserve maintainers most — LTS branches, versioning guidelines, better deprecation signals? - Interestingly I have not seen a document or page summarizing the volatily/stability/dynamics of Boost libraries. Surely the middle ground lies in understanding these challenges better. Even just identifying where users struggle the most could help cut through the fog and prevent maintainers from solving problems that may not actually exist. That kind of clarity could lead to a community-driven effort — or at the very least, offer maintainers better insight into the real needs of the broader user base. As a broader takeaway, it’s also important to acknowledge that what you’re asking for likely requires a communication-first approach. The community has already made significant strides here — from improving the website and documentation to making key information more accessible. These (huge) efforts deserve recognition, and they’re laying the groundwork for the kind of dialogue we need: between maintainers, between users, and especially between maintainers and users <3 Happy to help with sketching ideas, collecting feedback, or processing user input across platforms if that’s useful. That of course includes your input, Artyom :) Best wishes, Arno
(re-sent on list) On Sun, Aug 3, 2025, at 9:21 PM, Artyom Beilis wrote:
I honestly hope that Boost aims for something better than not the worst library to deal with It just clearly shows how broken the situation is.
So, if someone says «my experience isn't so problematic» or even «boost is not by far the worst of the pack», that is evidence of "how broken the situation is"? That is a logical inversion that doesn't fly for me.
What is needed is fixing the policies and creating some LTS versions... I don't understand how it isn't the _obvious_ thing for any SW developer.
I look around me and see them EVERYWHERE in package managers, whether with commercial LTS distro support or without. I do not see how adhering to LTS distribution versions doesn't fit your description. Mind you, it doesn't suit my use case because I require a higher level of control, but many projects just use Filesystem, Program Options and IOStreams... so yeah. That's fair game. If you're like me, you raise the deployment effort accordingly. It's different stances. There's something to be said for Boost to offer something akin to the stable subset (especially with modules around the corner), but I do not see the " large void" at the moment, that would be filled by it. Seth

On 3 Aug 2025 22:21, Artyom Beilis via Boost wrote:
What is needed is fixing the policies and creating some LTS versions... I don't understand how it isn't the _obvious_ thing for any SW developer.
LTS Boost branches might not be as useful as they may seem to address your complaints though. Instead of targeting a given Boost release (or rather, the set of releases that are compatible with your Boost usage) you would be targeting an LTS branch. Given that API/ABI between LTS branches may still break, this wouldn't be much different from the status quo. For example, you would still be dependent on a given LTS being available in a given Linux distro that you wish to target in your software. BTW, shipping multiple Boost versions in a single Linux distro is possible, and definitely has happened in the past, at least in Debian. From this perspective, shipping multiple LTS branches would also be no different from shipping multiple arbitrary Boost releases. So, what you're asking is to maintain backward API/ABI compatibility basically indefinitely, which just isn't feasible. Some API/ABI changes are necessary if we want Boost libraries to progress.

If boost was distributed as versioned modules and not as a monolithic source, it’s conceivable to institute some sort of API contract in meta data. But asking the current volunteer base to institute something globally when many users are consuming the code via a Linux distribution, that may or may not patch what they provide seems unreasonable. And which C++ version does the API apply to? And what if one library depends on another? Who fixes the old library without a maintainer? These guys do a GREAT job, but you forgot that the inventors of go, rust and python where all C++ programmers first, and that is why they built package management into the language. I just don’t think your request reasonable or feasible. Brian Sent from my iPhone
On Aug 5, 2025, at 9:07 AM, Andrey Semashev via Boost <boost@lists.boost.org> wrote:
On 3 Aug 2025 22:21, Artyom Beilis via Boost wrote:
What is needed is fixing the policies and creating some LTS versions... I don't understand how it isn't the _obvious_ thing for any SW developer.
LTS Boost branches might not be as useful as they may seem to address your complaints though. Instead of targeting a given Boost release (or rather, the set of releases that are compatible with your Boost usage) you would be targeting an LTS branch. Given that API/ABI between LTS branches may still break, this wouldn't be much different from the status quo. For example, you would still be dependent on a given LTS being available in a given Linux distro that you wish to target in your software.
BTW, shipping multiple Boost versions in a single Linux distro is possible, and definitely has happened in the past, at least in Debian.
From this perspective, shipping multiple LTS branches would also be no different from shipping multiple arbitrary Boost releases.
So, what you're asking is to maintain backward API/ABI compatibility basically indefinitely, which just isn't feasible. Some API/ABI changes are necessary if we want Boost libraries to progress.
_______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/LFJPKO5K...
чт, 31 июл. 2025 г. в 09:53, Artyom Beilis via Boost <boost@lists.boost.org>:
So quick google (and their gemeni) leads to examples exactly what I need: bp::child, wait, terminate, wait_for etc. Lots of tutorials fine.
This thread is actually amazing. We shouldn't change our APIs, because LLMs can get confused and hallucinate wrong snippets of code. Another point I also liked a lot is this:
No grace time, no deprecation, no keeping old API for a while (replacing headers with v1 is not backward compatibility it is a workaround) And honestly including huge dependency on Boost.Asio without "asking" is a problem.
The "no grace time, no deprecation" was immediately contradicted by the next email. The "including Asio dependency" looked very strange to me, as I vaguely remembered that Asio was always a dependency of Process. Luckily, we have Boost dependency reports online: https://pdimov.github.io/boostdep-report/boost-1.66.0/process.html. The key takeaway for me is that when asked for "concrete projects where that has been a problem" you came up with a *hypothetical* that you didn't even think through very well.
On Thu, Jul 31, 2025 at 3:48 PM Дмитрий Архипов <grisumbras@gmail.com> wrote:
чт, 31 июл. 2025 г. в 09:53, Artyom Beilis via Boost <boost@lists.boost.org>:
So quick google (and their gemeni) leads to examples exactly what I need: bp::child, wait, terminate, wait_for etc. Lots of tutorials fine.
This thread is actually amazing. We shouldn't change our APIs, because LLMs can get confused and hallucinate wrong snippets of code.
Agree! But it wasn't about LLM :-) I actually can care less about LLM. The point is If I used Boost.Process when I started my project 2 years ago or if I used the Boost.Process that Ihave with my distro it would become broken. But I used fork/exec code in the first place. And only when I tried to port it to windows I discovered that API was removed when 1.87 to 1.88. When v2 was introduced less than a year ago! (And requiring special definition - or touching the code is breaking) But this only a part of it (see below)
Another point I also liked a lot is this:
No grace time, no deprecation, no keeping old API for a while The "no grace time, no deprecation" was immediately contradicted by the next email.
Please notice that if v1 is hidden and requires special definition and version of 1.88 does not even mention how to enable v1 Quoting docs in 1.88
Version 2 is now the defauled. In order to discourage usage of the deprecated v1, it’s documentation has been removed.
This is now how you do stuff. Sorry! And this is only an example of how boost libraries tend to remove stuff (not first time!)
The "including Asio dependency" looked very strange to me, as I vaguely remembered that Asio was always a dependency of Process. Luckily, we have Boost dependency reports online: https://pdimov.github.io/boostdep-report/boost-1.66.0/process.html.
I stand corrected. My mistake.
The key takeaway for me is that when asked for "concrete projects where that has been a problem" you came up with a *hypothetical* that you didn't even think through very well.
It is a _real_ problem, not a _hypothetical one_. - If I introduce new code I shouldn't use a deprecated API. I may use some older API but not removed (hidden API) Because latest boost removed v1 and I don't know for how long it will stay - I need users to be able to build the project on normal Linux distro (like Ubuntu 2024 or 2020 that is still running) and that means I can't use Boost.Process on Linux. So Boost.Process is just not an option because I need to target more than a single system. So how did I solve it? Instead of moving from fork/exec/kill/wait on Linux to Boost.Process on Linux and Windows had to just use win32 API on Windows because Boost.Process API isn't useful! But what is important isn't Boost.Process itself. It is an issue across the entire boost code base. I hadn't been using boost in my projects for a while and when I finally needed a small library to do a simple task I discovered that nothing changed since I first started using Boost 1.33. It is all the same old story all over again. So I bring this back (not a first time) that Boost breaking APIs all the time should be addressed. Artyom
I would like to just go on record and say that I empathize with your complaints, Artyom. This actually comes back to the fundamentals of how Boost works. Boost, for the most part, is a set of independent developers doing whatever they want whenever they want. This is how Boost has essentially always worked. We give authors freedom to do as they please and this is just one of the consequences of that. We're not a paid product or a team working in a professional setting. So, I empathize with the frustrations that come from new Boost releases breaking things. I don't have any good off-hand solutions to your problems but I would just like to express that we're not all the same and won't accuse you of making up complaints because I've actually paid these maintenance burdens first-hand. I've shipped Asio code that's gone through a couple of radical API breaks and for the most part, while they are tenable, they do tend to require touching a lot of files and create some headaches. - Christian
Artyom Beilis wrote:
But we are not even in an API area. API is broken virtually every release.
I'm not sure that's quite correct, although it would obviously depend on how you measure "brokenness". "API" is "broken" even within the same release if you upgrade your compiler or you -std level. At the same time, more than half of all Boost libraries hardly change at all, so they can't be breaking API. But in addition to that, some libraries do break user code, but not because the API changed; rather, a PR or a fix introduces a bug or an incompatibility.
On 7 Jul 2025 15:45, Artyom Beilis via Boost wrote:
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation.
Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
FWIW, I've been actively using Boost in the projects I worked on for around 25 years now. Those were long-term projects, some lasted for a decade or more (while I worked on them) and some gradually transitioned from C++03 to C++17 in their lifetime. And yes, the Boost version that was used was being regularly upgraded while the projects were maintained and developed. And yes, we were building Boost ourselves. Granted, in those projects, we didn't care about ABI stability, but as for API stability, it's been surprisingly smooth considering the age and amount of changes that go into Boost. My experience may be subjective and not very representative, given that I'm also a Boost maintainer, but I really can't say that using Boost was "impossible" or "highly problematic". I admit there are use cases where ABI is much more important, but I also do not think stable ABI is a mandatory requirement in every use case. Stable ABI also has a cost; maintaining it just for the sake of it is a waste of effort and an obstacle to library evolution.
Hi. I am seeking an endorsement of my software, HMake ( a library in a way (hconfigure) ), so that it can go through the review and possibly be included in Boost as a modern replacement for b2. I recently released 0.3 of my software. I have posted an exhaustive list of benefits of my software earlier in this thread. I have added detailed documentation for the important API. And have completed implementation of non-scanning support of modules and header-unit in my HMake and in Clang https://github.com/llvm/llvm-project/pull/147682. Compiling this https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#boost-example results in 2.3x speed-up on my system. Instead of compiling my fork, you can use this https://drive.google.com/file/d/1agPjaVW65Ae10yUeuuqEGlh7WiigEiqg/view instead. Earlier I estimated the speedup to be >5x. My new estimate is >7x. Only 5 were successfully compiled as big-hu. And currently, shared memory BMI support is yet to be added in Clang. hmake.cpp of the Boost can be simplified a lot with a better front-end API. HMake has a great backend (BTarget, Builder, Node, TargetCache) and middle-end (CppTarget, CppSrc, CppMod, LOAT) API. However, its frontend API to create and feed the middle-end data structures can be further improved. Also, an invariant I followed while writing the hmake.cpp was to not modify the boost source-code at all. If there is some liberty to do that, the hmake.cpp could be so much simpler. In non-scanning build, the build-system needs a little more info like the list of header-files and header-units as not every header-file can be a header-unit. This could instead be supplied in a module-map file in a directory. In boost in Tests/ and Examples/ jam files every test has to be declared as run, compile, link, link-fail etc. Instead this info could be encoded in test name instead like r_test-name, c_test-name, cf_test-name. A file test-info could be further supplied which has the info about the output of the running tests. So, for now please review just the back-end and middle-end and be assured that completed hmake.cpp will be less than 1000 lines of easy to read and understand C++ code. With concerted, unanimous effort, it would take less than month to complete this. Best, Hassan Sajjad On Mon, Jul 7, 2025 at 8:59 PM Andrey Semashev via Boost < boost@lists.boost.org> wrote:
On 7 Jul 2025 15:45, Artyom Beilis via Boost wrote:
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation.
Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
FWIW, I've been actively using Boost in the projects I worked on for around 25 years now. Those were long-term projects, some lasted for a decade or more (while I worked on them) and some gradually transitioned from C++03 to C++17 in their lifetime. And yes, the Boost version that was used was being regularly upgraded while the projects were maintained and developed. And yes, we were building Boost ourselves. Granted, in those projects, we didn't care about ABI stability, but as for API stability, it's been surprisingly smooth considering the age and amount of changes that go into Boost. My experience may be subjective and not very representative, given that I'm also a Boost maintainer, but I really can't say that using Boost was "impossible" or "highly problematic".
I admit there are use cases where ABI is much more important, but I also do not think stable ABI is a mandatory requirement in every use case. Stable ABI also has a cost; maintaining it just for the sake of it is a waste of effort and an obstacle to library evolution.
_______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/ZU5UNK5U...
While you can read the documentation to see how HMake does header-units, you can instead run the boost example by following the following steps. Step - By - Step 1 You need Windows 2 You need the latest version of VS2022. 3 You need to compile my patch https://github.com/llvm/llvm-project/pull/147682 or you can instead use the pre-compiled binary https://drive.google.com/file/d/1agPjaVW65Ae10yUeuuqEGlh7WiigEiqg/view 4 Edit the last line of CppCompilerFeatures::initialize() to point to this fork 5 After downloading my software, you need to build it with CMake in Release mode with the latest visual-studio 2022. 6 Add the directory of the produced hhelper hbuild and htools in the path variable. I use clion and add the cmake-build-release. 7 Run htools with admin permissions. It create C:\Program Files (x86)\HMake\toolsCache.json file. 8 Download and un-zip from https://www.boost.org/releases/1.88.0/ 9 cd to the boost-1.88.0 10 copy the contents of HMake/Projects/Boost/* to here ( ArrayDeclarations.hpp and hmake.cpp) 11 mkdir Build 12 cd Build 13 hhelper 14 hhelper 15 cd huBig-d 16 ptime hbuild 17 cd ../conventional-d 18 ptime hbuild On my system conventional-d time was 2.3x higher than huBig-d time. Ultra-Fast Build is an experience of a kind. I have attached a sample output and screen-shots depicting colored output and a 10x speed-up in rebuild speed as well. To test rebuild, a random file Boost/libs/hash2/Tests/ripemd.cpp was edited. If endorsed and accepted, the whole boost can be compiled 7x faster in 1 month with all its configurations, docs and tests. On Thu, Dec 4, 2025 at 8:54 AM Hassan Sajjad <hassan.sajjad069@gmail.com> wrote:
Hi.
I am seeking an endorsement of my software, HMake ( a library in a way (hconfigure) ), so that it can go through the review and possibly be included in Boost as a modern replacement for b2. I recently released 0.3 of my software. I have posted an exhaustive list of benefits of my software earlier in this thread.
I have added detailed documentation for the important API. And have completed implementation of non-scanning support of modules and header-unit in my HMake and in Clang https://github.com/llvm/llvm-project/pull/147682. Compiling this https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#boost-example results in 2.3x speed-up on my system. Instead of compiling my fork, you can use this https://drive.google.com/file/d/1agPjaVW65Ae10yUeuuqEGlh7WiigEiqg/view instead. Earlier I estimated the speedup to be >5x. My new estimate is >7x. Only 5 were successfully compiled as big-hu. And currently, shared memory BMI support is yet to be added in Clang.
hmake.cpp of the Boost can be simplified a lot with a better front-end API. HMake has a great backend (BTarget, Builder, Node, TargetCache) and middle-end (CppTarget, CppSrc, CppMod, LOAT) API. However, its frontend API to create and feed the middle-end data structures can be further improved. Also, an invariant I followed while writing the hmake.cpp was to not modify the boost source-code at all. If there is some liberty to do that, the hmake.cpp could be so much simpler. In non-scanning build, the build-system needs a little more info like the list of header-files and header-units as not every header-file can be a header-unit. This could instead be supplied in a module-map file in a directory. In boost in Tests/ and Examples/ jam files every test has to be declared as run, compile, link, link-fail etc. Instead this info could be encoded in test name instead like r_test-name, c_test-name, cf_test-name. A file test-info could be further supplied which has the info about the output of the running tests. So, for now please review just the back-end and middle-end and be assured that completed hmake.cpp will be less than 1000 lines of easy to read and understand C++ code. With concerted, unanimous effort, it would take less than month to complete this.
Best, Hassan Sajjad
On Mon, Jul 7, 2025 at 8:59 PM Andrey Semashev via Boost < boost@lists.boost.org> wrote:
On 7 Jul 2025 15:45, Artyom Beilis via Boost wrote:
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation.
Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
FWIW, I've been actively using Boost in the projects I worked on for around 25 years now. Those were long-term projects, some lasted for a decade or more (while I worked on them) and some gradually transitioned from C++03 to C++17 in their lifetime. And yes, the Boost version that was used was being regularly upgraded while the projects were maintained and developed. And yes, we were building Boost ourselves. Granted, in those projects, we didn't care about ABI stability, but as for API stability, it's been surprisingly smooth considering the age and amount of changes that go into Boost. My experience may be subjective and not very representative, given that I'm also a Boost maintainer, but I really can't say that using Boost was "impossible" or "highly problematic".
I admit there are use cases where ABI is much more important, but I also do not think stable ABI is a mandatory requirement in every use case. Stable ABI also has a cost; maintaining it just for the sake of it is a waste of effort and an obstacle to library evolution.
_______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/ZU5UNK5U...
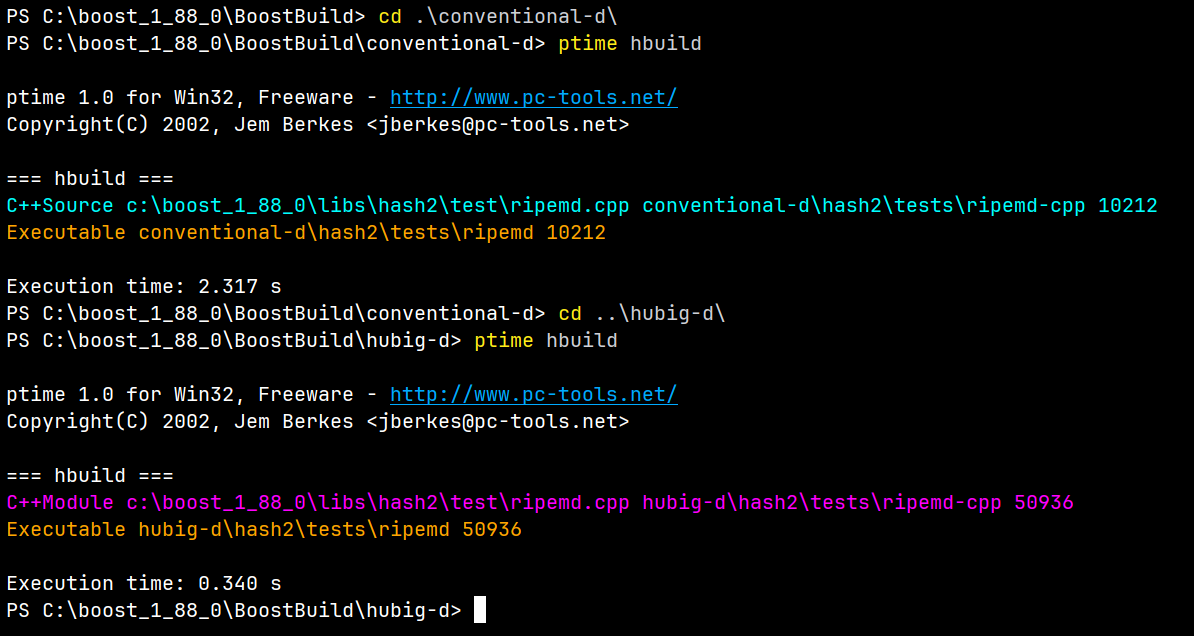{kind=link}
{kind=link}

On Sat, Dec 6, 2025, 10:40 Hassan Sajjad via Boost <boost@lists.boost.org> wrote:
If endorsed and accepted, the whole boost can be compiled 7x faster in 1 month with all its configurations, docs and tests.
This is not how Boost works though. Your work cannot be endorsed, reviewed and accepted ahead of time. Your proposal needs to be a complete working solution.

CMake represents the peak build system. You're flogging a dead horse. The last thing we need is Yet Another Quirky Build System. On Thu, 4 Dec 2025 at 06:59, Hassan Sajjad via Boost <boost@lists.boost.org> wrote:
Hi.
I am seeking an endorsement of my software, HMake ( a library in a way (hconfigure) ), so that it can go through the review and possibly be included in Boost as a modern replacement for b2. I recently released 0.3 of my software. I have posted an exhaustive list of benefits of my software earlier in this thread.
I have added detailed documentation for the important API. And have completed implementation of non-scanning support of modules and header-unit in my HMake and in Clang https://github.com/llvm/llvm-project/pull/147682. Compiling this https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#boost-example results in 2.3x speed-up on my system. Instead of compiling my fork, you can use this https://drive.google.com/file/d/1agPjaVW65Ae10yUeuuqEGlh7WiigEiqg/view instead. Earlier I estimated the speedup to be >5x. My new estimate is >7x. Only 5 were successfully compiled as big-hu. And currently, shared memory BMI support is yet to be added in Clang.
hmake.cpp of the Boost can be simplified a lot with a better front-end API. HMake has a great backend (BTarget, Builder, Node, TargetCache) and middle-end (CppTarget, CppSrc, CppMod, LOAT) API. However, its frontend API to create and feed the middle-end data structures can be further improved. Also, an invariant I followed while writing the hmake.cpp was to not modify the boost source-code at all. If there is some liberty to do that, the hmake.cpp could be so much simpler. In non-scanning build, the build-system needs a little more info like the list of header-files and header-units as not every header-file can be a header-unit. This could instead be supplied in a module-map file in a directory. In boost in Tests/ and Examples/ jam files every test has to be declared as run, compile, link, link-fail etc. Instead this info could be encoded in test name instead like r_test-name, c_test-name, cf_test-name. A file test-info could be further supplied which has the info about the output of the running tests. So, for now please review just the back-end and middle-end and be assured that completed hmake.cpp will be less than 1000 lines of easy to read and understand C++ code. With concerted, unanimous effort, it would take less than month to complete this.
Best, Hassan Sajjad
On Mon, Jul 7, 2025 at 8:59 PM Andrey Semashev via Boost < boost@lists.boost.org> wrote:
On 7 Jul 2025 15:45, Artyom Beilis via Boost wrote:
Removing C++03 compatability from many libraries and breaking Boost.ASIO in 1.87 seriously damaged the Boost reputation.
Boost breaking compatibility is the Achilles heel of Boost since I remember it (around 1.33) and it had never changed. It makes Boost highly problematic - almost irrelevant for any long term C++ project that needs to run over a large range of platforms that provide its own Boost. More than that, Boost is almost impossible to use in libraries or other interfaces because of breaking API/ABI virtually in any situation.
FWIW, I've been actively using Boost in the projects I worked on for around 25 years now. Those were long-term projects, some lasted for a decade or more (while I worked on them) and some gradually transitioned from C++03 to C++17 in their lifetime. And yes, the Boost version that was used was being regularly upgraded while the projects were maintained and developed. And yes, we were building Boost ourselves. Granted, in those projects, we didn't care about ABI stability, but as for API stability, it's been surprisingly smooth considering the age and amount of changes that go into Boost. My experience may be subjective and not very representative, given that I'm also a Boost maintainer, but I really can't say that using Boost was "impossible" or "highly problematic".
I admit there are use cases where ABI is much more important, but I also do not think stable ABI is a mandatory requirement in every use case. Stable ABI also has a cost; maintaining it just for the sake of it is a waste of effort and an obstacle to library evolution.
_______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at:
https://lists.boost.org/archives/list/boost@lists.boost.org/message/ZU5UNK5U...
_______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/K2GPJBCG...
On Sat, 6 Dec 2025 at 20:14, Vinnie Falco via Boost <boost@lists.boost.org> wrote:
On Sat, Dec 6, 2025 at 7:31 AM Richard Hodges via Boost < boost@lists.boost.org> wrote:
You're flogging a dead horse.
Please use animal-friendly terms, we don't do this here. Alternative: "you're feeding a fed horse."
Haha! Apologies! I'm still learning how to be an enlightened snowflake, even though it's going out of fashion.
Thanks _______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/YDIT2ZT5...

| With concerted, unanimous effort, it would take | less than month to complete this. My first question is if ninja is so slow, can it go faster? The reason I ask is that I use cmake/ninja day to day. It seems pretty optimal on the face of it. (The CPU cores seem generally busy with compiler and linker work) And I do tend to have ccache in the mix, also. And, my perception is that building boost doesn't really take that long (on Linux at least) so it's not obvious that being faster is so sought after. But perhaps a different story with other toolchains? - Nigel
| My first question is if ninja is so slow, can it go faster? HMake does fast compilation using C++20 header-units. CMake and Ninja cannot support that. See https://gitlab.kitware.com/cmake/cmake/-/issues/24616 and https://discourse.llvm.org/t/rfc-extensions-to-export-macros-preprocessor-st... . | And, my perception is that building boost doesn't really take that long (on Linux at least) so it's not obvious that being faster is so sought after. Boost + Tests and Examples HMake adoption could be a green signal for other mega projects for which the header-units advantage increases further. Like boost had been a flag-bearer for multiple modern C++ features in the past. On Sun, Dec 7, 2025 at 4:50 PM Nigel Stewart <nigels.com@gmail.com> wrote:
| With concerted, unanimous effort, it would take | less than month to complete this.
My first question is if ninja is so slow, can it go faster?
The reason I ask is that I use cmake/ninja day to day. It seems pretty optimal on the face of it. (The CPU cores seem generally busy with compiler and linker work) And I do tend to have ccache in the mix, also.
And, my perception is that building boost doesn't really take that long (on Linux at least) so it's not obvious that being faster is so sought after.
But perhaps a different story with other toolchains?
- Nigel
----- On Dec 7, 2025, at 1:37 PM, Hassan Sajjad via Boost boost@lists.boost.org wrote:
HMake adoption could be a green signal for other mega projects for which the header-units advantage increases further. Like boost had been a flag-bearer for multiple modern C++ features in the past.
Absolutely, HMake could then be promoted as the new bjam.
Absolutely, HMake could then be promoted as the new bjam.
bjam does not support c++20 modules or header-units. On Mon, Dec 8, 2025, 14:24 Alain O' Miniussi via Boost < boost@lists.boost.org> wrote:
----- On Dec 7, 2025, at 1:37 PM, Hassan Sajjad via Boost boost@lists.boost.org wrote:
HMake adoption could be a green signal for other mega projects for which the header-units advantage increases further. Like boost had been a flag-bearer for multiple modern C++ features in the past.
Absolutely, HMake could then be promoted as the new bjam.
_______________________________________________ Boost mailing list -- boost@lists.boost.org To unsubscribe send an email to boost-leave@lists.boost.org https://lists.boost.org/mailman3/lists/boost.lists.boost.org/ Archived at: https://lists.boost.org/archives/list/boost@lists.boost.org/message/4EW5RMJR...
ср, 16 апр. 2025 г. в 15:22, Hassan Sajjad via Boost <boost@lists.boost.org>:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
If this is a request for endorsement, then the problem is that the tool/library in question is not really documented. First, compare your README with CMake's tutorial https://cmake.org/cmake/help/latest/guide/tutorial/A%20Basic%20Starting%20Po... or B2's tutorial https://www.bfgroup.xyz/b2/manual/main/index.html#b2.tutorial. Both explain what file to create, what to put in there, what command to invoke from the shell. Your simple C++ example (https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#c-examples) starts in the middle of the file, and is definitely more hand-wavy. After reading the paragraphs following the code snippet I am not sure what commands I need to invoke. So, a supposed benefit of HMake is that you don't need to learn a new syntax. But learning a new library's API can be a significant task on its own. void updateBTarget(class Builder &builder, unsigned short round) override What is a "round" here? I am pretty well-versed in build system lingo, and I have no idea. In the following paragraph you explain that it is related to how C++ modules are built (in HMake and in CMake). There are no "rounds" in C++ modules spec or in CMake's document on how to use it with modules. So, this concept is particular to HMake. This highlights the fact that you need a thorough documentation of the API. WIthout it your tool/library is unusable in a serious scenario. Let's now compare a minimal C++ project in CMake, B2 and HMake. // HMake #include "Configure.hpp" void configurationSpecification(Configuration &config) { config.getCppExeDSC("app").getSourceTarget().sourceFiles("main.cpp"); } void buildSpecification() { getConfiguration(); CALL_CONFIGURATION_SPECIFICATION } MAIN_FUNCTION # CMake cmake_minimum_required(VERSION 3.12) project(Tutorial) add_executable(app main.cpp) #B2 exe app : main.cpp ; I don't see how HMake is an improvement. It's neither shorter nor more readable. For example, waht is "DSC"? This also highlights a common annoyance with using a regular programming language for build scripts: build scripts connect sources with targets, their names are strings, so you have to use a lot of quoting. Finally, let's consider getConfiguration. From the README I gather that the build script has to contain a description of every configuration that the project supports. That is, users can't experiment with a new configuration without modifying the build script. This is completely inadequate in my opinion. It is particularly inadequate for open source software projects. From the same description I gather that hmake also has to create a dedicated directory for each configuration. Note that the current main build system Boost uses (B2) does not work like that. It creates configurations on the fly from the user's build request and the targets' requirements. There's also no "active configuration" in B2, it can build multiple configurations simultaneously. My main point is still the lack of documentation. Without documentation there could be no discussion of endorsement, as we simply cannot evaluate what to endorse.

Hi, Sharing my thoughts so that the HMake author does not invest time unduly. Even with exceptional and detailed documentation, this feels like a high-risk change that’s very unlikely to take place without evidence of significant adoption elsewhere. Build systems are hard and most folk seem to prefer familiar foibles over innovation. If the build system space is interesting, it might be worth spending time improving existing tools (tooling around CMake is challenging) rather than starting from scratch. I’m happy to be wrong but don’t suspect that creating a new build system from scratch (without massive commercial backing) is likely to be a path of minimal resistance. J
On 6 May 2025, at 13:26, Дмитрий Архипов via Boost <boost@lists.boost.org> wrote:
ср, 16 апр. 2025 г. в 15:22, Hassan Sajjad via Boost <boost@lists.boost.org>:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
If this is a request for endorsement, then the problem is that the tool/library in question is not really documented. First, compare your README with CMake's tutorial https://cmake.org/cmake/help/latest/guide/tutorial/A%20Basic%20Starting%20Po... or B2's tutorial https://www.bfgroup.xyz/b2/manual/main/index.html#b2.tutorial. Both explain what file to create, what to put in there, what command to invoke from the shell. Your simple C++ example (https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#c-examples) starts in the middle of the file, and is definitely more hand-wavy. After reading the paragraphs following the code snippet I am not sure what commands I need to invoke.
So, a supposed benefit of HMake is that you don't need to learn a new syntax. But learning a new library's API can be a significant task on its own.
void updateBTarget(class Builder &builder, unsigned short round) override
What is a "round" here? I am pretty well-versed in build system lingo, and I have no idea. In the following paragraph you explain that it is related to how C++ modules are built (in HMake and in CMake). There are no "rounds" in C++ modules spec or in CMake's document on how to use it with modules. So, this concept is particular to HMake. This highlights the fact that you need a thorough documentation of the API. WIthout it your tool/library is unusable in a serious scenario.
Let's now compare a minimal C++ project in CMake, B2 and HMake.
// HMake #include "Configure.hpp" void configurationSpecification(Configuration &config) { config.getCppExeDSC("app").getSourceTarget().sourceFiles("main.cpp"); } void buildSpecification() { getConfiguration(); CALL_CONFIGURATION_SPECIFICATION } MAIN_FUNCTION
# CMake cmake_minimum_required(VERSION 3.12) project(Tutorial) add_executable(app main.cpp)
#B2 exe app : main.cpp ;
I don't see how HMake is an improvement. It's neither shorter nor more readable. For example, waht is "DSC"? This also highlights a common annoyance with using a regular programming language for build scripts: build scripts connect sources with targets, their names are strings, so you have to use a lot of quoting.
Finally, let's consider getConfiguration. From the README I gather that the build script has to contain a description of every configuration that the project supports. That is, users can't experiment with a new configuration without modifying the build script. This is completely inadequate in my opinion. It is particularly inadequate for open source software projects. From the same description I gather that hmake also has to create a dedicated directory for each configuration. Note that the current main build system Boost uses (B2) does not work like that. It creates configurations on the fly from the user's build request and the targets' requirements. There's also no "active configuration" in B2, it can build multiple configurations simultaneously.
My main point is still the lack of documentation. Without documentation there could be no discussion of endorsement, as we simply cannot evaluate what to endorse.
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
I’m happy to be wrong but don’t suspect that creating a new build system from scratch (without massive commercial backing) is likely to be a path of minimal resistance.
I stay motivated because HMake has a lot of benefits compared to the competitors. Commercial backing will indeed be seriously helpful. On Tue, May 6, 2025 at 6:43 PM Jonathan Coe via Boost <boost@lists.boost.org> wrote:
Hi,
Sharing my thoughts so that the HMake author does not invest time unduly.
Even with exceptional and detailed documentation, this feels like a high-risk change that’s very unlikely to take place without evidence of significant adoption elsewhere. Build systems are hard and most folk seem to prefer familiar foibles over innovation.
If the build system space is interesting, it might be worth spending time improving existing tools (tooling around CMake is challenging) rather than starting from scratch.
I’m happy to be wrong but don’t suspect that creating a new build system from scratch (without massive commercial backing) is likely to be a path of minimal resistance.
J
On 6 May 2025, at 13:26, Дмитрий Архипов via Boost < boost@lists.boost.org> wrote:
ср, 16 апр. 2025 г. в 15:22, Hassan Sajjad via Boost < boost@lists.boost.org>:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including
examples
and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning was as slow as the header-unit build.
If this is a request for endorsement, then the problem is that the tool/library in question is not really documented. First, compare your README with CMake's tutorial
https://cmake.org/cmake/help/latest/guide/tutorial/A%20Basic%20Starting%20Po...
or B2's tutorial https://www.bfgroup.xyz/b2/manual/main/index.html#b2.tutorial. Both explain what file to create, what to put in there, what command to invoke from the shell. Your simple C++ example (https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#c-examples ) starts in the middle of the file, and is definitely more hand-wavy. After reading the paragraphs following the code snippet I am not sure what commands I need to invoke.
So, a supposed benefit of HMake is that you don't need to learn a new syntax. But learning a new library's API can be a significant task on its own.
void updateBTarget(class Builder &builder, unsigned short round) override
What is a "round" here? I am pretty well-versed in build system lingo, and I have no idea. In the following paragraph you explain that it is related to how C++ modules are built (in HMake and in CMake). There are no "rounds" in C++ modules spec or in CMake's document on how to use it with modules. So, this concept is particular to HMake. This highlights the fact that you need a thorough documentation of the API. WIthout it your tool/library is unusable in a serious scenario.
Let's now compare a minimal C++ project in CMake, B2 and HMake.
// HMake #include "Configure.hpp" void configurationSpecification(Configuration &config) { config.getCppExeDSC("app").getSourceTarget().sourceFiles("main.cpp"); } void buildSpecification() { getConfiguration(); CALL_CONFIGURATION_SPECIFICATION } MAIN_FUNCTION
# CMake cmake_minimum_required(VERSION 3.12) project(Tutorial) add_executable(app main.cpp)
#B2 exe app : main.cpp ;
I don't see how HMake is an improvement. It's neither shorter nor more readable. For example, waht is "DSC"? This also highlights a common annoyance with using a regular programming language for build scripts: build scripts connect sources with targets, their names are strings, so you have to use a lot of quoting.
Finally, let's consider getConfiguration. From the README I gather that the build script has to contain a description of every configuration that the project supports. That is, users can't experiment with a new configuration without modifying the build script. This is completely inadequate in my opinion. It is particularly inadequate for open source software projects. From the same description I gather that hmake also has to create a dedicated directory for each configuration. Note that the current main build system Boost uses (B2) does not work like that. It creates configurations on the fly from the user's build request and the targets' requirements. There's also no "active configuration" in B2, it can build multiple configurations simultaneously.
My main point is still the lack of documentation. Without documentation there could be no discussion of endorsement, as we simply cannot evaluate what to endorse.
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
Hi. Thank you for a detailed comment. After reading the paragraphs following the code snippet I am not sure
what commands I need to invoke.
Yes. Now, I see it. I will add the following, and then the explanation. 1) htools with administrative permissions. 2) mkdir Examples/Example1/Build 3) cd Examples/Example1/Build 4) hhelper 5) hhelper 6) build ........ If you did not, do run this https://github.com/HassanSajjad-302/HMake/blob/main/Projects/Boost/hmake.cpp Let's now compare a minimal C++ project in CMake, B2 and HMake.
At scale, hmake.cpp will be much shorter. To be concise, expressive, and user-friendly is first priority. I don't see how HMake is an improvement. It's neither shorter nor more
readable. For example, waht is "DSC"?
Uhh. I will mention this in the documentation. This is short for "Dependency Specification Controller". This includes pointers to "CppSourceTarget" and "LinkOrArchiveTarget". If you set this line <https://github.com/HassanSajjad-302/HMake/blob/6f0ba0e3850f7008067af5ac3cd6bdf1de688735/CMakeLists.txt#L67> in CMakeLists.txt to "Examples/Example1/hmake.cpp", you get full intellisense for hmake.cpp file through ConfigureHelper and BuildHelper CMake targets. You can run/debug the configure and build steps by running these targets in build-dir. I am saying this because I had a comment before DSC template class declaration. Finally, let's consider getConfiguration. From the README I gather
that the build script has to contain a description of every configuration that the project supports. That is, users can't experiment with a new configuration without modifying the build script. This is completely inadequate in my opinion. It is particularly inadequate for open source software projects. From the same description I gather that hmake also has to create a dedicated directory for each configuration. Note that the current main build system Boost uses (B2) does not work like that. It creates configurations on the fly from the user's build request and the targets' requirements. There's also no "active configuration" in B2, it can build multiple configurations simultaneously.
Specifying new Configurations is very easy. Like boost/hmake.cpp had the following two configurations defined to benchmark the debug build with header-units. getConfiguration("conventional").assign(TreatModuleAsSource::YES, ConfigType::DEBUG); getConfiguration("hu").assign(TreatModuleAsSource::NO, TranslateInclude::YES, ConfigType::DEBUG); Creating build-dirs at build-time will be very slow. HMake creates these in parallel at configure-time. Also, this is a top-level API and can be modified per requirements. My main point is still the lack of documentation. Without
documentation there could be no discussion of endorsement, as we simply cannot evaluate what to endorse.
This is a recurrent complaint, so I concede. But I don't know where to start. I will be happy if you provide more ideas. Best, Hassan Sajjad On Tue, May 6, 2025 at 5:25 PM Дмитрий Архипов via Boost < boost@lists.boost.org> wrote:
ср, 16 апр. 2025 г. в 15:22, Hassan Sajjad via Boost < boost@lists.boost.org>:
Hi.
I compiled 25 Boost libraries with C++20 header-units, including examples and Tests of a few. This resulted in a 1.44x speed-up if we exclude the scanning. Scanning
was
as slow as the header-unit build.
If this is a request for endorsement, then the problem is that the tool/library in question is not really documented. First, compare your README with CMake's tutorial
https://cmake.org/cmake/help/latest/guide/tutorial/A%20Basic%20Starting%20Po... or B2's tutorial https://www.bfgroup.xyz/b2/manual/main/index.html#b2.tutorial. Both explain what file to create, what to put in there, what command to invoke from the shell. Your simple C++ example (https://github.com/HassanSajjad-302/HMake?tab=readme-ov-file#c-examples) starts in the middle of the file, and is definitely more hand-wavy. After reading the paragraphs following the code snippet I am not sure what commands I need to invoke.
So, a supposed benefit of HMake is that you don't need to learn a new syntax. But learning a new library's API can be a significant task on its own.
void updateBTarget(class Builder &builder, unsigned short round) override
What is a "round" here? I am pretty well-versed in build system lingo, and I have no idea. In the following paragraph you explain that it is related to how C++ modules are built (in HMake and in CMake). There are no "rounds" in C++ modules spec or in CMake's document on how to use it with modules. So, this concept is particular to HMake. This highlights the fact that you need a thorough documentation of the API. WIthout it your tool/library is unusable in a serious scenario.
Let's now compare a minimal C++ project in CMake, B2 and HMake.
// HMake #include "Configure.hpp" void configurationSpecification(Configuration &config) { config.getCppExeDSC("app").getSourceTarget().sourceFiles("main.cpp"); } void buildSpecification() { getConfiguration(); CALL_CONFIGURATION_SPECIFICATION } MAIN_FUNCTION
# CMake cmake_minimum_required(VERSION 3.12) project(Tutorial) add_executable(app main.cpp)
#B2 exe app : main.cpp ;
I don't see how HMake is an improvement. It's neither shorter nor more readable. For example, waht is "DSC"? This also highlights a common annoyance with using a regular programming language for build scripts: build scripts connect sources with targets, their names are strings, so you have to use a lot of quoting.
Finally, let's consider getConfiguration. From the README I gather that the build script has to contain a description of every configuration that the project supports. That is, users can't experiment with a new configuration without modifying the build script. This is completely inadequate in my opinion. It is particularly inadequate for open source software projects. From the same description I gather that hmake also has to create a dedicated directory for each configuration. Note that the current main build system Boost uses (B2) does not work like that. It creates configurations on the fly from the user's build request and the targets' requirements. There's also no "active configuration" in B2, it can build multiple configurations simultaneously.
My main point is still the lack of documentation. Without documentation there could be no discussion of endorsement, as we simply cannot evaluate what to endorse.
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
ср, 7 мая 2025 г. в 01:25, Hassan Sajjad <hassan.sajjad069@gmail.com>:
Specifying new Configurations is very easy. Like boost/hmake.cpp had the following two configurations defined to benchmark the debug build with header-units.
getConfiguration("conventional").assign(TreatModuleAsSource::YES, ConfigType::DEBUG); getConfiguration("hu").assign(TreatModuleAsSource::NO, TranslateInclude::YES, ConfigType::DEBUG);
Creating build-dirs at build-time will be very slow. HMake creates these in parallel at configure-time.
The issue here is not that it's hard to create new configurations. The issue is that the project's build scripts aren't an appropriate place for this. I shouldn't need to change files that are checked into version control system in order to just build the project for my system.
This is a recurrent complaint, so I concede. But I don't know where to start. I will be happy if you provide more ideas.
Meson (https://mesonbuild.com) is a relatively new build system. It has fairly well-organised and pretty documentation. You can start by copying its basic structure. You also definitely need a reference documentation for your library.
participants (28)
-
 Alain O' Miniussi
Alain O' Miniussi -
 Andrey Semashev
Andrey Semashev -
 Arnaud Becheler
Arnaud Becheler -
 Artyom Beilis
Artyom Beilis -
 Brian Kuhl
Brian Kuhl -
 Christian Mazakas
Christian Mazakas -
 cppleo@ya.ru
cppleo@ya.ru -
 Daniele Lupo
Daniele Lupo -
 Darryl Green
Darryl Green -
 Hassan Sajjad
Hassan Sajjad -
 Jakob Lövhall
Jakob Lövhall -
 Janko Dedic
Janko Dedic -
 Jean-Louis Leroy
Jean-Louis Leroy -
 John Maddock
John Maddock -
 Jonathan Coe
Jonathan Coe -
 Klemens Morgenstern
Klemens Morgenstern -
 Marcin Copik
Marcin Copik -
 Matt Gruenke
Matt Gruenke -
 Nigel Stewart
Nigel Stewart -
 oliver.kowalke@gmail.com
oliver.kowalke@gmail.com -
 Peter Dimov
Peter Dimov -
 René Ferdinand Rivera Morell
René Ferdinand Rivera Morell -
 Richard
Richard -
 Richard Hodges
Richard Hodges -
 Rob Boehne
Rob Boehne -
 Seth
Seth -
 Vinnie Falco
Vinnie Falco -
 Дмитрий Архипов
Дмитрий Архипов