
|
|
Boost-MPI : |
Subject: Re: [Boost-mpi] Suboptimal sending of std::vectors
From: Gonzalo Brito Gadeschi (g.brito_at_[hidden])
Date: 2014-01-21 12:24:37
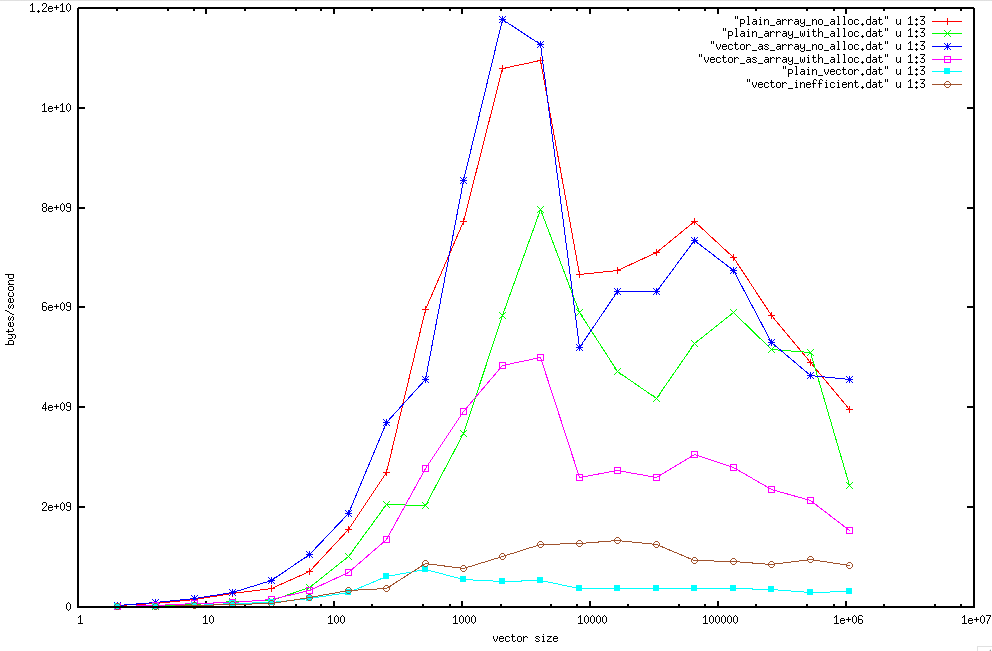
I've re-run your benchmarks (see attachments) using:
mpicxx -O3 -march=native -mtune=native -fstrict-aliasing
-fomit-frame-pointer -pipe -ffast-math -std=c++1y -pedantic -Wall
vector_send.cpp; mpirun -np 2 ./a.out
The compiler is clang tip-of-trunk (3.5 svn 21 january), libc++ is also
tip-of-trunk, and boost is 1.55. I've increased the #of iterations per
vector size to 1000.
First of all,
- MPI measurements in my system have an uncertainty similar to the
difference between vector and array without allocations.
- Memory allocation measurements in my system have an uncertainty similar
the difference between vector and array with allocations +- the MPI
measurement uncertainty.
Now a lot of guessing follows. When you use comm.recv(1,0,vector) I guess
that the vector is serialized and send as follows:
- process 1:
- allocates a buffer to serialize the vector
- copies the vector into the buffer
- sends the size of the buffer to 0
- send the buffer to 0
- process 0:
- receives the size of the buffer
- allocates a buffer to receive the vector
- receives the vector
- copies the vector data to the original vector (which might incur
multiple memory allocations)
I've tried to replicate this behavior in the "vector_inefficient" benchmark
which seems to agree well with the "vector" benchmark.
Can anyone with more knowledge of the Boost.MPI internals either confirm
this or explain what is really happening?
My best guess is that the performance problem comes from relying in the
generic boost::serialization for sending/receiving std::vector's. It is
just that for std::vector we can do the send with the pair (data(),size)
without allocating an extra buffer. The receive can be done with
resize(size) and using data() as receive buffer. I guess that the skeletons
are doing this.
Note 1: none of the above would be a problem if we were sending a std::map
or any other dynamic data structure.
Note 2: vector.resize default constructs the elements while malloc does
not (new does). That is, even in the best case sending a std::vector with
MPI is still more expensive than sending a plain C array although for cheap
to default construct types the difference should be minimal.
Don't know what is the best way to improve this. Boost.Serialization does
not seem to be the right place to do this optimization. Maybe overloading
send and recv methods for std and boost vectors will work.
Bests,
Gonzalo
On Mon, Jan 20, 2014 at 4:17 PM, Simon Etter <ettersi_at_[hidden]>wrote:
> Only in the plain array benchmark I don't measure memory allocation. For
> both the skeleton and plain array sending of a std::vector, the memory
> allocation (and zero initialization) is included in the benchmark. Since I
> am interested in the performance of sending an amount of data not
> previously known by the receiver, I would rather include the memory
> allocation also for the plain array benchmark. However, the plain array
> benchmark is only there to give an upper bound. To make my point, comparing
> the three benchmarks involving std::vectors is sufficient, and these three
> benchmarks should be equivalent in terms of the work that is done.
>
>
> On 20/01/14 15:37, Gonzalo Brito Gadeschi wrote:
>
>> You should call vector.reserve(n) before you call recv and benchmark
>> again because otherwise you are timing a memory allocation in the vector
>> benchmarks that isn't there in the array benchmarks.
>>
>> Bests,
>> Gonzalo
>>
>>
>>
>> On Mon, Jan 20, 2014 at 3:24 PM, Simon Etter <ettersi_at_[hidden]<mailto:
>> ettersi_at_[hidden]>> wrote:
>>
>> Hi!
>>
>> When benchmarking the performance of sending a std::vector<double>
>> with Boost.MPI, I noticed that you can gain several factors of speedup if
>> you replace
>>
>> std::vector<double> data(n);
>> comm.send(0,0,data);
>>
>> by e.g.
>>
>> std::vector<double> data(n);
>> comm.send(0,0, boost::mpi::skeleton(data));
>> comm.send(0,0, boost::mpi::get_content(data))__;
>>
>>
>> The code to benchmark, the measured data as well as a plot thereof
>> are attached. Further parameters were:
>>
>> MPI implementation: Open MPI 1.6.5
>> C++ compiler: gcc 4.8.2
>> Compiler flags: -O3 -std=c++11
>> mpirun parameter: --bind-to-core
>> CPU model: AMD Opteron(tm) Processor 6174
>>
>> Why is it/what am I doing wrong that the default sending of
>> std::vector<double> performs so badly?
>>
>> Best regards,
>> Simon Etter
>>
>> _______________________________________________
>> Boost-mpi mailing list
>> Boost-mpi_at_[hidden] <mailto:Boost-mpi_at_[hidden]>
>>
>> http://lists.boost.org/mailman/listinfo.cgi/boost-mpi
>>
>>
>>
>>
>> --
>> Dipl.-Ing. Gonzalo Brito Gadeschi
>> Institute of Aerodynamics and Chair of Fluid Mechanics
>> RWTH Aachen University
>> Wuellnerstraße 5a
>> D-52062 Aachen
>> Germany
>> Phone: ++49-(0)241-80-94821
>> Fax: ++49-(0)241-80-92257
>> E-mail: g.brito_at_[hidden] <mailto:g.brito_at_[hidden]>
>> Internet: www.aia.rwth-aachen.de <http://www.aia.rwth-aachen.de>
>>
>>
>>
>> _______________________________________________
>> Boost-mpi mailing list
>> Boost-mpi_at_[hidden]
>> http://lists.boost.org/mailman/listinfo.cgi/boost-mpi
>>
>> _______________________________________________
> Boost-mpi mailing list
> Boost-mpi_at_[hidden]
> http://lists.boost.org/mailman/listinfo.cgi/boost-mpi
>
-- Dipl.-Ing. Gonzalo Brito Gadeschi Institute of Aerodynamics and Chair of Fluid Mechanics RWTH Aachen University Wuellnerstraße 5a D-52062 Aachen Germany Phone: ++49-(0)241-80-94821 Fax: ++49-(0)241-80-92257 E-mail: g.brito_at_[hidden] Internet: www.aia.rwth-aachen.de
Boost-Commit list run by troyer at boostpro.com