
|
|
Boost Users : |
Subject: Re: [Boost-users] How efficient is the boost::regex library?
From: Brian Vandenberg (phantall+boost_at_[hidden])
Date: 2011-10-28 09:44:22
Adding to what John has said, if I may I'll offer some anecdotal advice.
Efficient use of regular expressions with /any/ implementation of a
regex library has a lot more to do with you writing an intelligent
regular expression, and knowing when it's appropriate to use them.
Certainly the engine helps, but if you write a stupid regular
expression, or attempt to use an RE for a task REs aren't well-suited
for, you won't get great results.
You can find corner cases where perl-compatible REs have poor
performance, but there are features offered that make it possible to
tweak that regular expression to get better performance.
I've used regular expressions from perl, ruby, python, C#, PCRE,
boost::regex, grep, awk, sed, mysql, postgres, and probably a few
others. Most commonly I prefer grep for one-liners, and
perl-compatible engines in code; I don't run into the corner cases in
my work for the simple fact that they're corner cases -- that is to
say, you don't run into them unless you're looking for them, or you do
something otherwise out-of-the-ordinary.
-Brian
On Fri, Oct 28, 2011 at 2:50 AM, John Maddock <boost.regex_at_[hidden]> wrote:
>> Thanks John. I would be interested in seeing comparisons of
>> boost:regex with other regex libraries.
>
> It's wildly out of date, but how about:
> http://www.boost.org/doc/libs/1_47_0/libs/regex/doc/vc71-performance.html
>
>> Yesterday I found a fuzzy logic string regex library. Does the
>> boost::regex library support this?
>
> No sorry,
>
> HTH, John.
>
> On Fri, Oct 28, 2011 at 5:10 AM, John Maddock <boost.regex_at_[hidden]>
> wrote:
>>>
>>> I am looking for the most efficient open-source C++ regex library.
>>>
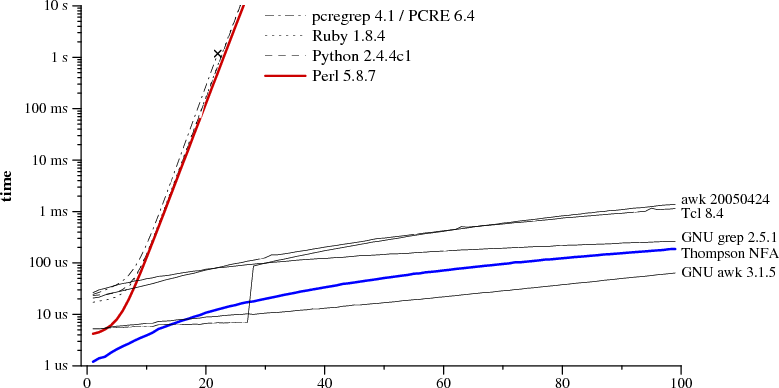
>>> Reading this article: http://swtch.com/~rsc/regexp/regexp1.html - It
>>> seems that GNU awk is the best overall:
>>> http://pdos.csail.mit.edu/~rsc/regexp-img/grep1p.png
>>
>> This is all true, but also completely irrelevant. DFA's have good worst
>> case behaviour, but can be many times slower for common cases. It's also
>> impossible to implement a DFA matcher that offers the full range of Perl
>> regular expression features (if you think it can be done, congratulations,
>> you've just proved that P==NP).
>>
>> It's also possible to protect the regex engine against runaway "bad"
>> expressions and bail out in those cases (this is what Boost.Regex does, it
>> throws an exception if the complexity of obtaining a match grows too
>> fast).
>>
>>> How does the boost::regex library compare?
>>>
>>> Would you recommend boost::regex as the most efficient one, or would
>>> you suggest another?
>>
>> There's no such thing as best - it all depends on the data being searched
>> and the particular regular expression. In addition since most
>> Perl-compatible libraries use much the same algorithm they're all broadly
>> similar albeit with different quirks.
>>
>> HTH, John.
>> _______________________________________________
>> Boost-users mailing list
>> Boost-users_at_[hidden]
>> http://lists.boost.org/mailman/listinfo.cgi/boost-users
>>
> _______________________________________________
> Boost-users mailing list
> Boost-users_at_[hidden]
> http://lists.boost.org/mailman/listinfo.cgi/boost-users
> _______________________________________________
> Boost-users mailing list
> Boost-users_at_[hidden]
> http://lists.boost.org/mailman/listinfo.cgi/boost-users
>
Boost-users list run by williamkempf at hotmail.com, kalb at libertysoft.com, bjorn.karlsson at readsoft.com, gregod at cs.rpi.edu, wekempf at cox.net
{kind=link}