
|
|
Boost : |
Subject: Re: [boost] [threadpool] version 22 with default pool
From: Edouard A. (edouard_at_[hidden])
Date: 2009-03-09 16:19:04
> > If you are using a kernel object to wait, you pay the cost of a
> transition
> > even if you don't have to wait.
>
> Sorry, I'm a little bit lost.
[Edouard A.]
My phrasing was confusing. I meant:
Even if you don't need to wait, you pay the cost of context switch when
accessing a kernel synchronization object.
> Boost.Interthreads has already this kind of free functions (wait()).
> Now that Boost.ThreadPool allows to check if the tread is a worker of
> a pool we can add a layer doing exactly that.
>
> What do you think?
The principle is good, however I'm afraid that you will add to the cost of
the waiting a nasty thing: poisoning. The threads that will wait will not be
able to schedule other useful tasks. Unless you wish to dedicate a pool for
this purpose.
In other news, I've improved the sorting function as you suggested:
template <typename RandomIterator, typename Pool> void
rec_pivot_partition(RandomIterator first, RandomIterator last, Pool & p) {
if (std::distance(first, last) > 1000)
{
RandomIterator pivot = pivot_partition(first, last);
boost::tp::task<void> task =
p.submit(boost::bind(&rec_pivot_partition<RandomIterator, Pool>,
boost::ref(first),
boost::ref(pivot),
boost::ref(p)));
rec_pivot_partition(pivot, last, p);
task.result().wait();
}
else
{
std::sort(first, last);
}
};
The results are much better, this time on a larger vector to account Phil's
remark:
std::fill reverse 0..10000000 elapsed: 0.039 ok : 1
tbb::parallel_for fill 0..10000000 elapsed: 0.016 ok : 1
std::sort reverse 0..10000000 elapsed: 1.172 ok : 1
tbb::parallel_sort reverse 0..10000000 elapsed: 0.269 ok : 1
boost::tp::sort reverse 0..10000000 elapsed: 0.331 ok : 1
This should not be seen as a real benchmark for a parallel_sort
implementation - there are many more cases to evaluate when it comes to
sorting - but I think it's safe to say that TBB is significantly more
efficient. That should not discourage anyone of course: TBB is a mature
library with a lot of skilled people working on it.
I also increased the size of the block to 10,000 and performance improved a
little bit (to ~ 0.316). If I increase to 100,000, performance go back to ~
0.331.
I initially set up the slice to 1,000 because that's the size of a slice in
TBB. I wanted - first of all - to compare the engines.
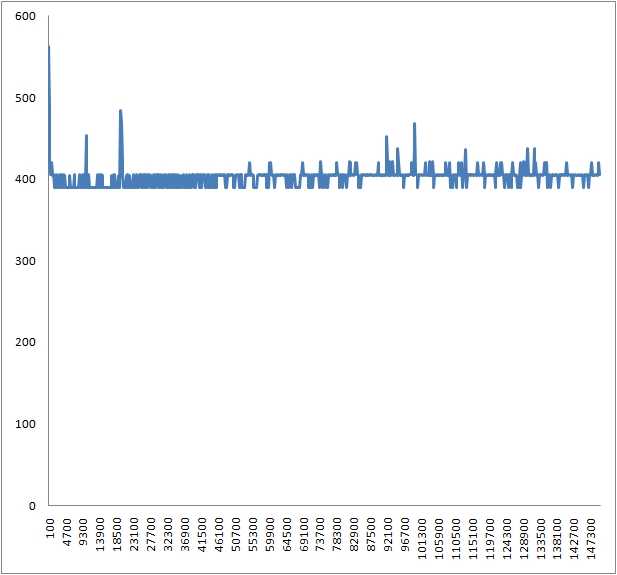
I've run a test with sizes between 100 and 150,000 and it seems to have
little impact on the outcome. This is strange. It's a bit early to say if
it's bad news. See csv & graph attached. I've used GetTickCount to measure.
We should perhaps do a test where we would inject large amount of tasks of
precise duration and see how the scheduler behaves. It would also be
interesting to measure the delay of execution of one of the tasks (if you
know a task should last 1 s, measure how long it actually took).
Kind regards.
-- EA
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk